IBE7 Week 4 · 21 พ.ค. 2026 · Gen AI Vibe Code (Concept + Prototype) AI in the Scale ERA จาก prompt เดียว สู่ workflow ระดับองค์กร — เรียนรู้ว่าธุรกิจ SME ใช้ Claude ย่นงานที่เคยใช้เวลาเป็นเดือนให้เหลือเพียงนาทีได้อย่างไร และจะขยายขึ้นเป็นระบบที่ governed (กำกับดูแลได้), auditable (ตรวจสอบย้อนกลับได้) รองรับการทำงานข้ามทีมได้อย่างไร · วันนี้เราจะปูแนวคิด "Vibe Coding" ใน Session A แล้วลงมือสร้าง Application ใช้งานได้จริงด้วย Claude ใน Session B
IBE7 · Future SME Intelligence · NIA × SCB SME · หมายเหตุสำหรับ Facilitator แสดงเป็นตัวเอียง · ไฟล์ตัวอย่างประกอบ: ./sample_data/
Today's Map · IBE7 Week 4 · 21 พ.ค. 2026 วันนี้เราจะเรียนรู้อะไรกันบ้าง แบ่งเป็นสองช่วงหลัก — Session A ปูแนวคิด "Vibe Coding" ให้แน่น (45 นาที) จากนั้น Session B ลงมือสร้าง Application ใช้งานได้จริงด้วย Claude (1 ชั่วโมง 45 นาที) · เนื้อหา Part 3-4 จัดไว้เป็น reference (อ้างอิง) เพื่อให้ทุกท่านนำกลับไปทบทวนและต่อยอดเองที่บ้าน
เปิด deck บนเครื่องของท่าน สแกน QR เพื่อดู deck ควบคู่ระหว่าง workshop หรือเปิดผ่าน URL: ibe7-vibe-code.harmonyx.workers.dev
เลือกภาษาได้ที่หน้าแรก · เปิด tab ค้างไว้เพื่อ scroll ตามและคัดลอก prompt ใน Session B ได้
14:15 – 15:00 · 45 นาที Session A — Concept (ปูพื้นฐานความเข้าใจ) บทนำ · AI in the Scale ERA Vibe Coding 101 — แนวคิดจาก Andrej Karpathy (2025) Claude Wrap-Up — สรุปสิ่งใหม่ที่นำไปใช้งานได้จริง BPMN — ภาษากลางสำหรับออกแบบ Automation 15:15 – 17:00 · 1 ชม. 45 นาที Session B — Prototype Workshop (ลงมือสร้างจริง) Demo #1 — Beginner · สกัดและจัดหมวด feedback ลูกค้า Demo #2 — Intermediate · BPMN process จากงานจริง Demo #3 — Advanced · สร้าง Mini-App ใช้งานจริงด้วย Claude Reference (อ้างอิงประกอบ) Part 3 — Scale AI Harness — โครงนั่งร้านของ Agent จาก MiniApp สู่ Enterprise App เส้นทาง SME → PCL (วัดระดับความพร้อม) ESG & Reporting (เชื่อมโยงกับ Week 4) Take home (ต่อยอดเพิ่มเติม) Part 4 — ต่อยอดเพิ่มเติม Durable vs Disposable — สิ่งที่ควรลงทุนเทียบกับสิ่งที่เปลี่ยนเร็ว Starter Pack — checklist สำหรับวันจันทร์หน้า FAQ — security, cost, governance และ rollout Session A · แนวคิดที่ในยุคนี้ Vibe Coding คืออะไร — และทำไมเราถึงพูดถึงในปี 2026 คำที่ Andrej Karpathy (อดีต Director of AI ที่ Tesla และอดีตผู้ร่วมก่อตั้ง OpenAI) นิยามไว้เมื่อกุมภาพันธ์ 2025 — บรรยาย intent (ความต้องการ) เป็นภาษามนุษย์ ปล่อยให้ AI สร้าง code แล้ว iterate (ปรับซ้ำเป็นรอบ ๆ) ตามความรู้สึก โดยไม่จำเป็นต้องอ่าน code ทีละบรรทัด
"ผมยอมจำนนต่อ Vibe Coding อย่างเต็มที่ เปิดรับ การเติบโตแบบทวีคูณ และลืมไปเลยว่ายังมี code อยู่"
— Andrej Karpathy, Feb 2025
3 ลักษณะสำคัญของ Vibe Coding 01 Intent-first (เริ่มจากความต้องการ) บรรยายปัญหาและผลลัพธ์ที่ต้องการ ไม่ต้องระบุ implementation (วิธีเขียน code) ทีละขั้น — "อยากได้ app ที่ทำหน้าที่ A" แทนคำสั่งแบบ "เขียน for-loop ที่..."
02 Iterate by feel (ปรับโดยใช้ความรู้สึก) รันแล้วดูผล หากยังไม่ใช่ ก็แก้ prompt แล้วลองใหม่ — ท่านไม่ต้อง debug ตัว code แต่ debug คำอธิบายของตนเองแทน
03 AI คือ developer · คุณคือ PM บทบาทสลับกัน — ท่านเป็นผู้ตัดสินว่า "ใช่หรือยังไม่ใช่" ส่วน Claude เป็นผู้เขียน รัน ทดสอบ และแก้ไข code — เปรียบเสมือนการ brief requirement (สื่อสารความต้องการ) ให้กับ senior developer มืออาชีพ
Vibe Coding คือส่วนหนึ่งของ "AI Engineering" — สาขาใหม่ที่ไม่ใช่ ML Engineering แบบเดิม Chip Huyen ในหนังสือ AI Engineering (2025) ได้สรุปไว้ว่า การสร้าง app ด้วย foundation model นั้นแตกต่างจาก ML Engineering แบบดั้งเดิมใน 3 ประเด็นสำคัญ — และนี่คือเหตุผลที่ Vibe Coding ถือเป็น "วินัย" อย่างแท้จริง มิใช่เพียง meme
01 ปรับโมเดล ไม่ใช่สร้างโมเดล ไม่จำเป็นต้องสร้างโมเดลขึ้นเอง — ใช้โมเดลที่ Anthropic, OpenAI ฯลฯ ได้ฝึกไว้แล้ว · ลักษณะงานจึงเปลี่ยนจาก "training" ไปสู่ "adaptation" (prompt → RAG → finetune)
02 โมเดลใหญ่ขึ้น compute หนักขึ้น Foundation model ใช้ compute มากกว่าและมี latency สูงกว่า ML รุ่นก่อนอย่างมีนัยสำคัญ · ดังนั้น inference optimization (caching, batching, model picker) จึงสำคัญตั้งแต่วันแรก
03 Output แบบเปิด → evaluation ยาก ML รุ่นเก่าตอบ "ใช่/ไม่ใช่" — ตรวจสอบได้ง่าย · ส่วน Foundation model ตอบเป็นข้อความยาว ไม่มี ground truth เพียงคำตอบเดียว · evaluation จึงกลายเป็นปัญหาใหม่ที่ใหญ่ที่สุดของ AI Engineering
Workflow ที่กลับด้าน — และทำไม Vibe Coding ถึงเร็ว ML Engineering (แบบเดิม)
Data → Model → Product
เก็บ data ก่อน → ฝึก model → สร้าง product · ใช้เวลาหลายเดือนกว่า user คนแรกจะได้สัมผัส
AI Engineering (Vibe Coding)
Product → Data → Model
สร้าง product ก่อน → เก็บ data จากการใช้งานจริง → ค่อยลงทุนใน model · ลงทุนใน data และ model เฉพาะ product ที่พิสูจน์แล้วว่ามี traction
"AI Engineering workflow มอบรางวัลให้แก่ทีมที่ iterate ได้รวดเร็ว" — Shawn Wang, 2023 · นี่คือเหตุผลที่ 3 demo ของวันนี้ ล้วนเริ่มต้นจาก Product เสมอ
เหมาะกับงานแบบไหน — และไม่เหมาะกับงานแบบไหน ✓ เหมาะกับ Prototype & MVP Internal tools (เครื่องมือใช้ภายใน) Demo / proof-of-concept Automation script (สคริปต์ทำงานอัตโนมัติ) งานสำรวจ data / prompt experiment △ ต้อง review ก่อน production ระบบเก็บข้อมูล sensitive (PII, การเงิน) Auth / payment / billing ระบบที่ต้องมี audit trail (ตรวจสอบย้อนได้) Regulated industries (อุตสาหกรรมที่มีกฎกำกับ) สาระสำคัญ (Key Takeaway) Vibe Coding มิใช่ "การหยุดเขียน code" — แต่คือ "การย้ายเส้นแบ่งว่าอะไรนับเป็น code ออกไป" · งานที่เคยใช้เวลา 2 สัปดาห์ ปัจจุบันใช้เพียง 2 ชั่วโมง · งานที่เคยต้องว่าจ้าง developer ปัจจุบัน business owner (เจ้าของธุรกิจ) ดำเนินการได้ด้วยตนเอง · Session A จะเจาะลึกว่ามีอะไรเปลี่ยนไปบ้าง ส่วน Session B เราจะลงมือสร้างของจริงด้วยกัน
Session A · ลูปที่ทำงานจริง 4 ขั้นตอนของ Vibe Coding Loop แทนที่ลูป "เขียน → debug → แก้ code" แบบเดิม ลูปใหม่คือ "บรรยาย → ให้ AI สร้าง → รัน → ปรับคำบรรยาย" · ดูเรียบง่ายแต่ทักษะใหม่ที่ต้องฝึก คือ การเลือกใช้คำบรรยายให้ AI ตีความได้ตรงตามที่ท่านต้องการ
1. Describe (บรรยายความต้องการ) บอก context + intent + รูปแบบ output ที่ต้องการ · ตัวอย่าง: "ผมอยากได้ web app หน้าเดียวที่รับ CSV ของ feedback ลูกค้า แล้ว classify เป็น positive/neutral/negative — แสดงผลเป็น table"
💡 หากมีข้อจำกัดทาง tech stack ให้ระบุไว้ตั้งแต่ต้น (เช่น "ใช้ React + Tailwind" หรือ "ไม่ต้องมี database")
2. Generate (ปล่อยให้ AI สร้าง) Claude จะเขียน code ครบทั้งไฟล์ · ใน Claude.ai → ปรากฏเป็น Artifact (แสดง preview ทันที) · ใน Claude Code → เขียนไฟล์ลงใน project ของท่านโดยตรง · ยังไม่ต้องอ่าน code ทีละบรรทัด — รอดู output ก่อน
💡 หาก output ยาวเกินไป ขอเป็น "เฉพาะ section ที่เปลี่ยน" หรือ "diff format"
3. Run (รันดูผลทันที) Artifact รันบน browser ทันที · Claude Code รันใน terminal · ตรวจสอบ 3 ประเด็น: (1) ทำงานได้หรือไม่ (2) ผลลัพธ์ตรงตามที่ต้องการหรือไม่ (3) edge case (กรณีพิเศษ) ใดที่นึกออก — จดบันทึกสิ่งที่ผิดพลาดไว้ทันที
💡 ยังไม่ต้องแก้ code ด้วยตนเอง — รอบที่ 4 จะส่ง feedback กลับให้ AI ปรับแก้
4. Refine (ปรับคำบรรยาย) แทนที่จะแก้ code ท่านแก้ prompt แทน · "ปรับตรงนี้เป็น…แทน" หรือ "ถ้า input ว่างให้…" หรือ "ทำสีให้สวยขึ้น ดู professional กว่าเดิม" · วนรอบจนกว่าจะพอใจ
💡 หากวน 3 รอบแล้วยังไม่ดีขึ้น แนะนำให้เริ่มใหม่ด้วย prompt ที่ละเอียดกว่าเดิม (อย่าฝืนแก้ต่อ)
ตัวอย่าง prompt ที่ใช้จริงในแต่ละขั้น Describe (รอบแรก) "สร้าง React app ที่ให้ user upload CSV (มี column: id, message, date). แสดงเป็น table มี filter ตาม sentiment. ใช้ Tailwind. ไม่ต้อง backend — ทำใน browser อย่างเดียว"
Refine (รอบที่ 2-3) "เพิ่ม dropdown filter ตาม category · ใส่ summary card ด้านบนบอกจำนวนรวมของแต่ละ sentiment · เปลี่ยน color scheme เป็น dark mode · ถ้า CSV ผิด format ให้แสดง error message ที่ชัดเจน"
สาระสำคัญ (Key Takeaway) Vibe Coding ไม่ใช่ "การป้อน prompt เพียงครั้งเดียวแล้วได้ผลลัพธ์ที่สมบูรณ์" — แต่คือ "การวนรอบเล็ก ๆ ให้ครบและรวดเร็ว" · 1 รอบใช้เวลา 30 วินาที – 2 นาที · 10 รอบ = app ที่ใช้งานได้ภายใน 20–30 นาที · ทักษะที่ต้องฝึก คือ การมองเห็นความต่างระหว่างผลที่ได้กับผลที่ต้องการ แล้วระบุออกมาเป็นประโยคสั้น ๆ ให้ AI เข้าใจ
Claude ในปี 2026 อยู่ตรงไหน
Claude Wrap-Up — อะไรเปลี่ยน อะไรสำคัญ
การเปลี่ยนแปลงสำคัญสามประการที่ส่งผลต่อการทำงานประจำวัน —
มิใช่เพียงรายการคุณสมบัติ แต่เป็นการเปลี่ยนแปลงที่เปิดทาง use case
ใหม่
Shift 1
จาก Chat → Agent
Claude ไม่เพียงตอบคำถาม แต่วางแผน เรียกใช้ tool ทำซ้ำ และตรวจสอบผลด้วยตนเองได้
— หน่วยของงานเปลี่ยนจาก "1 คำตอบ" เป็น "1 งานที่เสร็จสมบูรณ์"
Shift 2
จาก Prompt → Skill
องค์ความรู้ที่ใช้ซ้ำได้ ถูกบรรจุเป็น
Skill, Plugin, MCP — สร้างครั้งเดียว
นำกลับมาใช้ได้ทั่วทั้งองค์กร prompt
ที่ดีจึงกลายเป็นสินทรัพย์ขององค์กร
Shift 3
จาก Sandbox → System
เชื่อมต่อเข้ากับไฟล์ ปฏิทิน CRM และ ERP ผ่าน
MCP Connector — AI
มิได้เป็นเพียงเครื่องมือเสริม แต่ทำงานอยู่ในระบบงานหลักโดยตรง
3 ความสามารถที่ต้องเข้าใจวันนี้
ความสามารถ
คืออะไร
ใช้ตอนไหน
Skills
คำสั่งสำเร็จรูปที่ Claude โหลดมาใช้ตามความต้องการ (เช่น
docx, xlsx,
finance:reconciliation)
งานที่ทำซ้ำ มี pattern ตายตัว
MCP Connectors
มาตรฐานเปิดที่ให้ Claude อ่าน/เขียนข้อมูลใน tool ที่คุณใช้อยู่
(Drive, GitHub, ERP, …)
ทุกที่ที่ข้อมูลอยู่นอกหน้าต่างแชท
Sub-agents / Plans งานหลายขั้น แบ่งทีม ทำขนานกัน ตรวจซ้ำ
งานที่ใหญ่กว่า 1 prompt
MCP ในปี 2026 — สถานะของ ecosystem
17K+
servers ที่ index ไว้ใน public registry (Q1 2026)
9.4K
servers ที่ active · เติบโต +18% MoM ตลอด Q1
78%
ของทีม enterprise AI มี MCP agent บน production (เม.ย. 2026)
v1.27
เพิ่ม OAuth 2.1 + Gateway + audit — พร้อมสำหรับ Stage 4 governance
MCP servers ที่มีจริงในปัจจุบัน: Salesforce · HubSpot · Confluence · Notion · SharePoint · Jira · ServiceNow · Drive · GitHub · Slack · PostgreSQL · Stripe · Figma · และอีก 200+ ตัวจาก community
6 Prompt patterns ที่ใช้ซ้ำได้
อุตสาหกรรมในปี 2026 มาตรฐานเป็น
"prompt pattern library" — บรรจุเก็บไว้
ใช้ได้กับทุก task แทนการเขียน prompt ใหม่จากศูนย์ทุกครั้ง
1
Chain-of-thought
"คิดทีละขั้น (think step-by-step) แล้วค่อยตอบ" — เพิ่มความแม่นยำในงานที่ต้องใช้เหตุผลหลายขั้น
2
Few-shot examples
แสดงตัวอย่าง input/output 2-3 คู่ใน prompt — Claude เรียนรู้ pattern ที่ต้องการได้ทันที
3
Output schema
"ตอบในรูปแบบ JSON ตาม schema นี้: ..." — รับประกันว่า output นำไปใช้ต่อในระบบได้
4
Role framing
"คุณคือ senior auditor กำลังตรวจ..." — เปลี่ยน register และระดับ rigor ของคำตอบทันที
5
Self-critique loop
"ร่างคำตอบ → วิจารณ์ → ปรับปรุง" — pattern ที่ Opus 4.7 ทำเป็น native แล้ว · ยังคงใช้ได้กับ Sonnet/Haiku
6
Negative constraints
"อย่าทำ X" บางครั้งทำงานได้ดีกว่า "ทำ Y" — โดยเฉพาะการป้องกัน failure mode ที่เคยพบ
Demos ทั้ง 3 ของวันนี้ใช้ patterns 1, 2, 3 อยู่แล้ว ·
pattern 5 จะปรากฏใน AI Harness ·
pattern 4 ปรากฏใน ESG Demo
3 วิธีปรับแต่ง foundation model (Adaptation Techniques)
เมื่อ prompt เพียงอย่างเดียวยังไม่เพียงพอ — ในงานจริง AI engineer ทุกคนจะไต่บันได 3 ขั้นนี้ตามลำดับ ·
ขั้นต่ำใช้ data น้อย ขั้นสูงใช้ data มาก ราคาแพงและซับซ้อนยิ่งขึ้น · หลักการ:
ทดลองขั้นที่ง่ายที่สุดก่อนเสมอ
(อ้างอิง: Chip Huyen, AI Engineering , 2025)
ขั้น 1 · เริ่มที่นี่
Prompt Engineering
ปรับ behavior ของโมเดล โดยไม่แตะ weight ของโมเดลเลย — เพียงใช้คำสั่งและ context
ก็เพียงพอสำหรับ use case ส่วนใหญ่ · ใช้ data 0–10 ตัวอย่าง · ทดลองได้ภายในไม่กี่นาที
Demo ทั้ง 3 ของวันนี้ใช้ขั้นนี้ทั้งหมด
ขั้น 2 · เพิ่ม knowledge
RAG (Retrieval-Augmented Generation)
เชื่อม Claude เข้ากับ knowledge base ขององค์กร — ดึงข้อมูลที่เกี่ยวข้องเข้ามาประกอบ prompt ในทุกรอบที่เรียกใช้ ·
เหมาะอย่างยิ่งสำหรับ เอกสาร นโยบาย และ FAQ ภายในองค์กร ที่โมเดลไม่เคยพบเห็น
Demo #2 (policy markdown) เป็น RAG เวอร์ชันที่เรียบที่สุด
ขั้น 3 · ขั้นสุดท้าย
Finetuning
ฝึกต่อบนข้อมูลขององค์กรเอง — เปลี่ยนแปลง weight ของโมเดล · ใช้ data
หลักร้อยถึงหลักหมื่นตัวอย่าง · ช่วยลด latency และ cost ในระยะยาว แต่ใช้เวลาและทรัพยากรค่อนข้างมาก
เริ่มพิจารณาเมื่อ prompt + RAG ยังไม่ถึง quality bar ที่ต้องการ
หลักการสำคัญ: เริ่มต้นจาก prompt engineering เสมอ — เพราะรวดเร็ว ต้นทุนต่ำ และเปิดโอกาสให้ท่านทดลองกับโมเดลหลายตัว เพิ่มโอกาสค้นพบโมเดลที่ "พอดี" กับงานของท่าน · ขยับขึ้นขั้นถัดไปก็ต่อเมื่อ prompt engineering พิสูจน์แล้วว่าไม่เพียงพอ
5 Failure modes — และวิธีกู้คืน
Demo ทั้งหมดในวันนี้แสดง happy path · ในการใช้งานจริง Claude
จะพบ failure mode เหล่านี้ในบางครั้ง — สิ่งที่แยกทีมที่ "ใช้
Claude ได้" จากทีมที่ "บ่นว่า Claude ไม่น่าเชื่อถือ" คือ
การรู้ pattern และ recovery prompt
01
ปฏิเสธไม่ตอบ (Refusal)
อาการ: "I can't help with that..." · เหตุ: request กำกวมหรือดูเสี่ยง · แก้: เพิ่ม business context — "ฉันเป็น compliance manager ของบริษัท X กำลังตรวจ..."
02
Hallucination
อาการ: ตัวเลข/ชื่อ/วันที่ที่ไม่มีในต้นทาง · เหตุ: ไม่มี source ที่ ground · แก้: "ตอบเฉพาะจากเอกสารที่แนบ · ถ้าไม่มี ให้ตอบ 'ไม่ระบุในเอกสาร'"
03
Schema break
อาการ: output ไม่ใช่ valid JSON · เหตุ: ไม่ระบุ schema ชัด · แก้: ให้ JSON schema เต็ม + "ถ้าค่าไหนไม่แน่ใจ ให้ใส่ null · ห้ามแต่งขึ้นมา"
04
Length drift
อาการ: ตอบยาวเกินหรือสั้นเกินไป · เหตุ: ไม่กำหนดขอบเขต · แก้: ระบุจำนวน "5 bullets, แต่ละข้อ ≤ 20 คำ" · ถ้าเกิน chunk input ก่อน
05
Tone drift
อาการ: เสียง casual ใน formal context · เหตุ: ไม่มี role framing · แก้: "คุณคือผู้สอบบัญชี SOX · เขียนแบบที่จะปรากฏใน annual report"
Recovery
Retry-with-correction
เมื่อ output ผิด อย่ารัน prompt เดิมซ้ำ · ส่งกลับ: "Output ที่ผ่านมามีปัญหา [X] · รันใหม่ โดยรับประกันว่า [Y]" — Claude แก้เฉพาะจุดที่ระบุ ไม่ใช่เดาเอง
เลือกโมเดล + ประมาณการค่าใช้จ่าย (May 2026)
คำถามแรกของ CFO เสมอ: "จะใช้ Claude เดือนละกี่บาท?" —
ตารางนี้ให้คำตอบที่ตรงไปตรงมา keyed ตาม use case
โมเดล ความเร็ว ราคา / M tokens เหมาะกับ Demo ที่ตรงกัน
Haiku 4.5 เร็วที่สุด
$1 in / $5 out
งานปริมาณมาก รูปแบบชัดเจน · classification, triage, simple extract
Demo #1 (จัดหมวด feedback)
Sonnet 4.6 สมดุล
$3 in / $15 out
Workflow ทั่วไป · reasoning + tool use + multi-step
Demo #2, #3, ESG Demo
Opus 4.7 ลึกที่สุด
$5 in / $25 out
Reasoning ซับซ้อน · code · planning หลายขั้น · self-verification
Three-Agent orchestrator
2 กลไกลด cost ที่ควรเปิดใช้ตั้งแต่วันแรก
−90%
Prompt caching
System prompt ยาว + เอกสารอ้างอิงที่ใช้ซ้ำ — cache 5 นาที · input tokens ที่ cache hit เสีย เพียง 10% ของราคาปกติ · จำเป็นมากสำหรับ skill ที่รันบ่อย
−50%
Batch API
งานที่ไม่ต้องการ real-time (รายงาน · scheduled brief · content batch) — ส่งเข้า batch API · ราคาลดครึ่ง · ผลกลับภายใน 24 ชม.
ตัวอย่าง SME 10 คน — รัน skill แบบ Demo #1 จำนวน 200 ครั้ง/วัน × 30 วัน = 6,000 ครั้ง × ~5K tokens ≈ 30M tokens/เดือน · Haiku ดิบ: $30/เดือน · เปิด caching: $5-10/เดือน · คืนทุนตั้งแต่ process แรกที่ดำเนินการ automate
สาระสำคัญ (Key Takeaway)
หน่วยของงาน AI กำลังเปลี่ยนจาก
"1 คำตอบ (one answer)" →
"1 task ที่เสร็จสมบูรณ์ (one completed task)" —
prompt ที่เคยใช้เพียงครั้งเดียวจึงสามารถกลายเป็น Skill
ที่ทั้งทีมนำกลับมาใช้ซ้ำได้
ทดสอบความเข้าใจ · Quick Check Skill,
MCP Connector, และ Sub-agent ต่างกันอย่างไร? เลือกใช้ตอนไหน?
Skill = pattern ที่ทำซ้ำได้
บรรจุไว้ใช้งานทั่วทั้งองค์กร ·
MCP (Model Context Protocol) = ช่องทางเชื่อม AI
เข้ากับ tool/ข้อมูลภายนอก · Sub-agent =
ย่อยงานขนาดใหญ่ออกเป็นหลายขั้นเพื่อทำงานแบบขนาน — เลือกใช้ Skill
เมื่อมีงานซ้ำ · MCP เมื่อข้อมูลอยู่นอก chat · Sub-agent
เมื่องานมีขนาดใหญ่กว่า 1 prompt
Business Process Management Notation
BPMN — ภาษากลางของ automation
ก่อนการ automate ควรเริ่มจากการวาดแผนภาพ — BPMN
เป็นสัญลักษณ์ที่กระชับ ทำให้ทีม business และทีม tech สื่อสารเรื่อง
workflow เดียวกันได้อย่างตรงกัน
4 สัญลักษณ์หลักที่จำเป็น
● Event
เหตุการณ์ที่เกิดขึ้น — มีการ submit form, อีเมลเข้า, หรือ timer
ครบเวลา
▭ Task
งานที่ดำเนินการ — โดยบุคคล โดย Claude หรือโดยระบบ
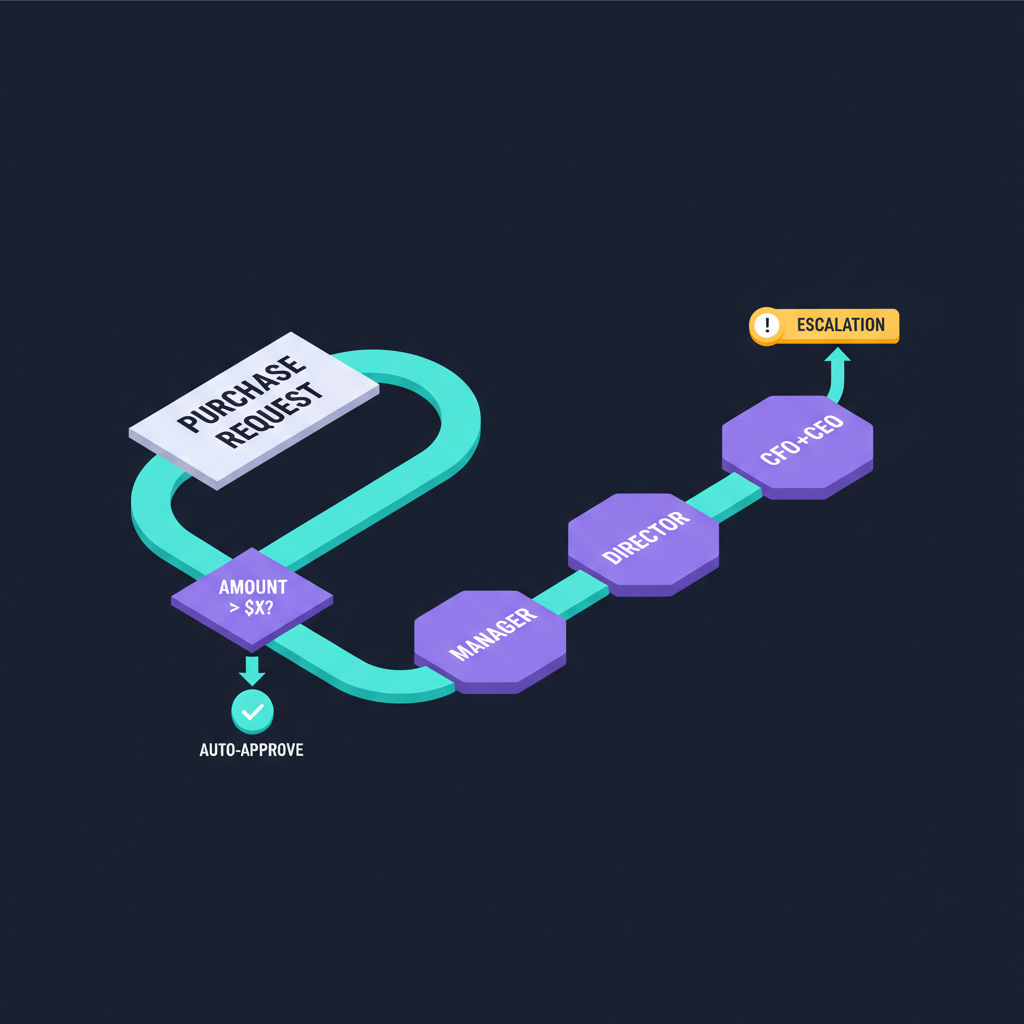
◇ Gateway
จุดตัดสินใจ — "หากยอดเกิน 5K ส่งต่อให้ Finance Director"
→ Flow
ทิศทางของงาน — กำหนดว่าใครส่งอะไรให้ใคร
ตัวอย่าง BPMN จริง ที่จะใช้ใน Demo #2
รับ PR
ตรวจ Vendor
ส่งให้ Approver
แจ้งผู้ขอ
ออก PO
Gateway แยกตาม amount_usd: 1K auto · 1K–5K Manager
· 5K–15K Finance Dir · ≥15K CFO+CEO
เหตุใด BPMN จึงสำคัญในยุค AI
1. กำหนดขอบเขตของ prompt
เมื่อวาดเป็นแผนภาพได้ จะทราบชัดเจนว่างานใดที่ Claude รับผิดชอบ
และงานใดที่ยังต้องการการตัดสินใจจากบุคคล
2. ระบุข้อมูลที่ต้องใช้
ลูกศรแต่ละเส้นคือ payload —
การตั้งชื่อลูกศรช่วยระบุได้ทันทีว่าต้องใช้ CSV, document หรือ
API ใด
3. ใช้เป็นหลักฐาน audit ได้
เมื่อมีการตรวจสอบ — BPMN ประกอบกับ run log ของ Claude
คือชุดหลักฐานสำหรับการ compliance ที่ครบถ้วน
ทำไม BPMN ถึงเป็นการลงทุนที่ future-proof
BPMN เป็น
ISO/IEC 19510 มาตั้งแต่ 2013 ใช้งานจริงมาตั้งแต่
2004 — โมเดล AI เปลี่ยนทุก 6 เดือน, framework เกิดใหม่ทุกปี, แต่
BPMN ที่คุณวาดวันนี้จะยังใช้ได้ในปี 2030 —
เป็นภาษาที่ทั้ง business, tech, auditor, และ AI
ตัวต่อไปเข้าใจตรงกันหมด · ดู
slide Durable vs Disposable ประกอบ
สาระสำคัญ (Key Takeaway)
วาด BPMN ก่อนเขียน prompt — process
มีอายุการใช้งานยาวกว่าโมเดลทุกรุ่นที่มาทดแทน เครื่องมือเปลี่ยน
แต่แผนภาพยังคงอยู่
ทดสอบความเข้าใจ · Quick Check ในตัวอย่าง PR Approval ถ้าจะเพิ่ม policy "vendor ต้องลงทะเบียน
VAT" ต้องเพิ่ม element BPMN ใดบ้าง?
เพิ่ม Gateway 1 ตัว หลัง "ตรวจ Vendor" —
หากไม่ได้ลงทะเบียน VAT → branch ไปยัง
Task ใหม่ "แจ้ง Procurement ขอเอกสาร" —
เพิ่มเฉพาะ Gateway และ Task โดยไม่ต้องแก้ไข Event
ต้นทางหรือปลายทาง · นี่คือเหตุผลที่ BPMN เป็นภาษากลาง —
สามารถเพิ่มเงื่อนไขใหม่ได้โดยไม่จำเป็นต้อง redesign ทั้งระบบ
Session B · เลือก surface ก่อนเริ่ม เครื่องมือไหน — สำหรับงานแบบไหน Vibe Coding ไม่ได้ผูกติดกับ tool เพียงตัวใดตัวหนึ่ง — แต่ละ surface (เครื่องมือ) มีจุดเด่นต่างกัน · กฎง่าย ๆ: ต้องการ prototype เร็ว ๆ บน browser → Artifacts · ทำงานกับไฟล์ / repo (คลังโค้ด) ของจริง → Claude Code · web framework เฉพาะทาง → v0 / Bolt · ทำงานบน IDE → Cursor
หลัก 2 ตัวที่เราใช้วันนี้ Primary Claude.ai — Artifacts ทำงานบน browser · ไม่ต้องติดตั้งใด ๆ · พิมพ์ prompt → Claude สร้าง Artifact (ผลลัพธ์: React / HTML / Python / SVG / ฯลฯ) → preview รันให้ดูทันทีข้าง chat · iterate (ปรับซ้ำ) ได้อย่างรวดเร็ว · แชร์ผ่าน URL ได้ทันที
เหมาะกับ Prototype (ต้นแบบ) ของ single-page app Demo สำหรับนำเสนอ stakeholder (ผู้มีส่วนได้ส่วนเสีย) ทดสอบแนวคิด (idea) ภายใน 10 นาที Data visualization (การแสดงผลข้อมูล) และ dashboard ขนาดเล็ก Primary Claude Code (CLI) ทำงานบน terminal · เข้าถึง folder / repo (คลังโค้ด) ของท่านโดยตรง · Claude อ่าน / เขียนไฟล์ของจริง รัน command ได้ และทำงานร่วมกับ git ได้ · เหมาะกับ codebase ที่มีอยู่แล้ว มากกว่ากรณีเริ่มจากศูนย์ (zero-to-one)
เหมาะกับ แก้ไข / เพิ่ม feature ใน codebase จริง Refactor (ปรับโครงสร้าง) หลายไฟล์พร้อมกัน Automation script (สคริปต์อัตโนมัติ) + file processing (ประมวลผลไฟล์) Integration (เชื่อมต่อ) กับ git, npm, build tools เครื่องมือเสริม (รู้ไว้ใช้เลือก) v0.dev Vercel เฉพาะทาง Next.js + shadcn/ui · จุดเด่นคือ UI ที่หน้าตาเรียบร้อยตามมาตรฐาน · deploy ขึ้น Vercel ได้ในคลิกเดียว · เหมาะกับ landing page, marketing site และ dashboard
Bolt.new StackBlitz Full-stack (ครบทั้ง front + back) บน browser · Node + frontend อยู่ในที่เดียวกัน · มี file tree (โครงสร้างไฟล์) ที่แสดงชัดเจน · เหมาะกับ MVP ที่ต้องการ backend logic
Cursor IDE VS Code fork ที่ผสาน AI ไว้ในตัว · เหมาะหากท่านคุ้นเคยกับ IDE (Integrated Development Environment) อยู่แล้ว · ทำงานบน local repo ของท่านเอง · มี Cmd+K สำหรับ rewrite (สั่งเขียนใหม่) พร้อม chat ในแถบด้านข้าง
Decision Tree (ตัดสินใจเร็วๆ) หากท่านต้องการ... เลือกใช้ เพราะ ทดลอง idea ภายใน 10 นาที — ไม่ต้องการตั้ง project Claude.ai Artifacts เปิด tab พิมพ์ prompt และเห็นผลทันที แก้ไข / เพิ่ม feature ใน codebase ที่มีอยู่ Claude Code อ่าน / เขียนไฟล์ของจริง เข้าใจ context ของ project สร้าง landing page หน้าตาดี และ deploy บน Vercel v0.dev ถนัด UI components และมี deploy ในตัว สร้าง MVP full-stack ที่ต้องการ Node backend Bolt.new Frontend + backend อยู่ใน browser เดียว ทำงานบน IDE อยู่แล้ว ต้องการให้ AI ช่วยใน editor Cursor ใช้ VS Code muscle memory ได้ พร้อม AI ในตัว
สาระสำคัญ (Key Takeaway) วันนี้เราเลือกใช้ Claude.ai Artifacts เป็นหลัก (Demo 1–3) เพราะเปิดได้เร็วและไม่ต้องติดตั้งใด ๆ · ท่านที่มี repo (คลังโค้ด) อยู่แล้ว สามารถทดลองใช้ Claude Code ควบคู่กันได้ · ส่วน adjacent tools (เครื่องมือเสริม) ให้ทราบไว้เป็น vocabulary (คำศัพท์อ้างอิง) เพื่อหยิบมาใช้ในภายหลังเมื่อเจองานที่เหมาะสม
1
Beginner · ~20 นาที · Claude.ai Artifacts
สร้าง Feedback Classifier App เป้าหมาย วันนี้เราไม่ได้เพียงป้อน prompt เท่านั้น — แต่จะ vibe-code สร้าง "web app หน้าเดียว (single-page app)" ที่ผู้ใช้ upload CSV ของ feedback ลูกค้า แล้วได้ผลลัพธ์ classify (จัดหมวด) เป็น positive / neutral / negative พร้อม summary · เป้าหมาย: เปิด Claude.ai → ทำให้เสร็จภายใน 20 นาที → ได้ app ที่ใช้งานได้จริงและส่งต่อให้คนอื่นใช้ได้
ข้อมูลตัวอย่าง ใช้ไฟล์ตัวอย่าง 60 ข้อความที่ column sentiment ยังเว้นว่างไว้ — app ที่เราสร้างจะเป็นตัวเติมให้
Surface (เครื่องมือ) ที่ใช้: Claude.ai Artifacts เปิด browser → claude.ai → เริ่ม new chat · พิมพ์ prompt → Artifact preview จะปรากฏข้าง chat ทันที · iterate (ปรับซ้ำ) ได้รวดเร็ว ไม่ต้องติดตั้งใด ๆ
Loop (ลูป) ที่จะใช้วันนี้ Describe → Generate → Run → Refine · ทั้งหมด 3 รอบ · ใช้เวลาประมาณ 5 นาทีต่อรอบ
รอบที่ 1 — Describe (เริ่มต้น) Prompt เขียนเป็นภาษาอังกฤษเพื่อความแม่นยำของ output Prompt · Round 1
Copy Build a single-page React app (use Tailwind, no backend) where I can paste
in CSV text with columns: id, message, date.
The app should:
1) Parse the CSV in-browser
2) For each row, classify sentiment as positive / neutral / negative
(use a simple keyword + rule heuristic — Claude does NOT need to call
an API for this demo)
3) Show results as a sortable table with columns: id, message (truncated),
sentiment (color-coded badge), date
4) Show a summary card on top with counts per sentiment
Use clean spacing, IBM Plex Sans, a neutral palette + one accent color. รอบที่ 2 — Refine (เพิ่ม category filter + polish) Prompt · Round 2
Copy Now add:
- A category dropdown to filter the table (categories: Bug, Billing, Praise,
Feature Request, Question, UX, Performance — pick best fit per row)
- A search box that filters by message text
- Make it look like a Stripe / Linear product: more spacing, hover states,
card shadows, micro-interactions on filter changes รอบที่ 3 — Refine (export + edge case) Prompt · Round 3
Copy Final round:
- Add an "Export labelled CSV" button that downloads the table as CSV
with the original columns + sentiment + category
- If the pasted CSV is malformed, show a clear error message
(not a crash)
- Add an empty-state when no CSV is pasted yet ผลที่ผู้เข้าร่วมจะได้ App ที่ใช้งานได้จริง รันอยู่ใน Artifact ของ Claude.ai · paste CSV เข้าไป → ได้ผล classify ทันที · มี filter และ export พร้อมใช้
Share ได้ทันที Artifact มี share URL · ส่งให้เพื่อนร่วมงาน เปิดได้บน browser ของเขาทันที โดยไม่ต้องติดตั้งใด ๆ
Iteration loop (ลูปปรับซ้ำ) ที่นำไปใช้ต่อได้ เห็นแล้วว่า 3 รอบสั้น ๆ สร้าง app ขนาดเล็กได้ · ทักษะนี้นำไปประยุกต์ใช้กับงานอื่นได้ทันที
สาระสำคัญ (Key Takeaway) Demo 1 ไม่ใช่ "Claude ทำ classification ให้ครั้งเดียว" — แต่คือ "เรา vibe-code สร้าง app classification ขึ้นมาด้วยตนเอง" · ความแตกต่างคือ: prompt ของเราก่อให้เกิด app ที่คนอื่นยังหยิบไปใช้งานต่อได้ ไม่ใช่ output ที่ใช้ครั้งเดียวแล้วทิ้ง
ทดสอบความเข้าใจ · Quick Check รอบที่ 1 ไม่ได้ระบุว่าให้ใช้ "API" หรือ "AI model" สำหรับ classify — ทำไม? เพราะเป้าหมายของ Demo 1 คือการสาธิต loop ของ vibe coding ไม่ใช่ accuracy (ความแม่นยำ) ของตัว model · keyword heuristic (เกณฑ์ตามคำสำคัญ) ทำให้ app รันบนเครื่องของผู้ใช้ได้ทันทีโดยไม่ต้องเชื่อม API · ใน production (ระบบใช้งานจริง) ค่อยเพิ่ม API call ภายหลังได้ · กฎคือ: simplify (ทำให้เรียบง่าย) ก่อน แล้วเพิ่ม complexity (ความซับซ้อน) เมื่อจำเป็น
2
Intermediate · ~35 นาที · Claude.ai Artifacts
สร้าง PR Triage Dashboard เป้าหมาย Demo 2 ยกระดับขึ้นมาอีกขั้น — เราจะสร้าง "PR Triage Dashboard (แดชบอร์ดคัดกรองคำขอซื้อ)" ที่ Finance Officer (เจ้าหน้าที่การเงิน) เปิดใช้งานในแต่ละเช้า · upload PR CSV + paste นโยบาย (markdown) → ได้ table แสดง approver (ผู้อนุมัติ), SLA, flags (ข้อสังเกต) พร้อม email draft (ร่างอีเมล) 3 ฉบับ · ผู้ใช้แก้ policy บน UI ได้ → table อัปเดตทันที (ไม่ต้อง redeploy หรือขึ้นระบบใหม่)
ข้อมูลตัวอย่าง BPMN — หลายขั้น + แตกแขนง PR เข้า
ตรวจ Vendor
Approver
Approver
?
แจ้งเตือน
PO / Reject
2 gateway: ตามยอดเงิน + ตาม flag exception (กรณียกเว้น)
Policy ที่ใช้ในตัวอย่าง ยอดเงิน (USD) ผู้อนุมัติ SLA < 1,000 Auto-approve (ถ้า vendor เป็น preferred) ทันที 1,000 – 4,999 Department Manager 1 วันทำการ 5,000 – 14,999 Finance Director 2 วันทำการ ≥ 15,000 CFO + CEO (dual sign) 3 วันทำการ
รอบที่ 1 — Describe (เริ่มต้น) Prompt · Round 1
Copy Build a single-page React app (Tailwind, no backend) — a "PR Triage
Dashboard" for finance officers.
Layout:
- Left panel: textarea where the user pastes the approval policy (markdown).
Default-populate it with this:
[paste 02_approval_policy.md contents here]
- Right panel: a file input that accepts a CSV of purchase requests
(columns: pr_id, vendor_id, amount_usd, category, msa_on_file)
When a CSV is uploaded:
- Parse it in-browser
- For each row, compute approver + SLA + flags by READING the markdown
policy from the left panel (do simple keyword + threshold parsing)
- Show results as a table: pr_id | amount | approver | sla_due | flags | rationale
- Show summary cards on top: total PRs, auto-approved, escalated, flagged
Style: clean dashboard look. IBM Plex Sans. Neutral palette + one accent. รอบที่ 2 — Refine (เพิ่ม vendor check + email) Prompt · Round 2
Copy Add a third input: a vendor master CSV (columns: vendor_id, name,
tax_id_verified, risk_rating, preferred).
Update the triage logic:
- If tax_id_verified=No OR risk_rating=High → flag NEEDS_LEGAL
- If category=Professional Services and msa_on_file=No → flag NEEDS_MSA
For each PR, also generate 3 email drafts (collapsible per row):
1) to requester: status + next step
2) to approver: 1-paragraph context + ask
3) exception report to CFO (only for flagged rows)
Add an "expand all" / "collapse all" toggle. รอบที่ 3 — แก้ Policy แล้วเห็นผลทันที Prompt · Round 3
Copy The key feature for the demo:
- Every keystroke in the policy textarea re-runs the triage and updates
the table in real-time (debounce 300ms is fine)
- Show a small "policy version" indicator (count of edits since load)
- Add a "Reset to default policy" button
Then add a one-line "Why?" explanation in each rationale cell — pulled
from the matching line in the policy markdown. รอบที่ 4 — Polish + export Prompt · Round 4
Copy Final round:
- "Export decision pack" button: downloads a zip with (a) decision CSV,
(b) the 3 email drafts as .eml files, (c) the policy snapshot used
- Make it look like Linear / Notion: more whitespace, subtle shadows,
rounded corners, smooth hover states on rows
- Handle empty/malformed CSVs with a clear error state
- Add a small "live" indicator pulsing when re-triage runs ประเด็นสำคัญ Compliance Policy ≡ UI markdown ใน textarea คือตัวระบบ · แก้ที่นี่ → พฤติกรรมของระบบเปลี่ยน · audit trail ใช้ "policy version" counter ที่นับให้
Exceptions บุคคลพิจารณาเฉพาะเคสที่ต้องใช้วิจารณญาณ App จะ auto-approve กรณีที่ชัดเจน · flag เฉพาะรายการที่ต้อง escalate ส่งต่อให้คนพิจารณา
Output Decision pack ส่งออกได้ทันที Decision CSV + email .eml + policy snapshot รวมใน zip เดียว — พร้อมสำหรับ audit และส่งต่อให้ผู้อนุมัติ
สาระสำคัญ (Key Takeaway) Demo 2 แสดงพลังของ vibe coding ในระดับ "internal tool (เครื่องมือใช้ภายในองค์กร)" — สิ่งที่เคยต้องว่าจ้างทีม developer ใช้เวลา 2–3 สัปดาห์ ปัจจุบันสร้างได้ใน 35 นาทีบน Claude.ai · ที่สำคัญที่สุด: business owner (เจ้าของธุรกิจ) แก้ policy ได้ด้วยตนเอง โดยไม่ต้องผ่าน developer คอยช่วย · เหมาะอย่างยิ่งกับ workflow ประเภท rule-based (อิงเกณฑ์ที่กำหนด) ที่เปลี่ยนแปลงบ่อย
ทดสอบความเข้าใจ · Quick Check ทำไม policy ต้องอยู่ใน UI (textarea) ไม่ใช่ฝังใน prompt? เพราะ "policy ที่ฝัง (embed) ไว้ใน prompt" มีสถานะเทียบเท่ากับ code — ทุกครั้งที่ policy เปลี่ยน ก็ต้องกลับไปแก้ prompt บน Claude.ai ซึ่ง business owner ทำเองไม่ได้ · ส่วน "policy บน UI" = ผู้ใช้แก้ไขได้ทันที, ระบบบันทึก version ให้, audit (ตรวจสอบย้อนหลัง) ได้ · นี่คือกฎสำคัญของ vibe coding ระดับ internal tool: แยก rule (กฎ — ที่เปลี่ยนบ่อย) ออกจาก code (ที่เปลี่ยนไม่บ่อย) ให้ชัดเจน
3
Advanced · ~45 นาที
SME Operations Mini-App — agent ครบ loop
สถานการณ์
ในทุกเช้า ผู้บริหารต้องตรวจสอบข้อมูล 4 ด้าน: ยอดขายของวันก่อนหน้า สต็อกที่ใกล้หมด คิว support และลูกค้าสำคัญที่ต้องติดตาม — workshop นี้จะสร้าง Morning Briefing ที่ใช้ prompt เพียงตัวเดียว ดึงข้อมูลทั้ง 4 ด้านมาประมวลผล จัดลำดับความสำคัญ และร่าง action ให้พร้อมดำเนินการในวันนั้น — เป็น mini-app ที่ทั้งทีมสามารถหยิบไปใช้งานได้
ข้อมูลตัวอย่าง
BPMN — agent orchestrate 4 sub-task ขนาน
↳
Sub-agent A
· ยอดขายรายวัน
↳
Sub-agent B
· ความเสี่ยงสต็อกหมด
↳
Sub-agent C
· Support SLA
↳
Sub-agent D
· สุขภาพลูกค้า Top
⇢
ประกอบ Brief
Email / Slack
รัน demo — prompt
prompt เก็บเป็นภาษาอังกฤษเพื่อความแม่นยำ
Prompt
Copy
You are our morning ops agent. Run four checks in parallel against
the four CSVs in sample_data/ and produce ONE brief.
A. Sales — yesterday vs last 7d average. Flag any region or SKU
moving ±25%. Compute revenue, top SKU, slowest channel.
B. Inventory — list any SKU where on_hand_qty reorder_point.
For each, estimate days-to-stockout from last 7d velocity.
C. Support — list any ticket with priority=High AND age_hours 24,
or any ticket with age_hours 72. Group by area.
D. Customers — surface any Gold/Platinum customer with open_tickets0.
Then write the brief:
- Top 3 actions for today (with owner + 1-line "why")
- Risks to watch this week
- 3 draft replies to the most overdue Support tickets
Tone: tight, founder-friendly, no fluff.
ทำไมถือเป็น "Advanced"
Multi-tool
อ่าน 4 แหล่ง
Sales + stock + ticket + customer — สังเคราะห์เป็นข้อสรุปที่นำไปใช้ได้จริง มิใช่เพียงดัมพ์ข้อมูลออกมา
Parallel
Sub-agents
การตรวจแต่ละด้านรันเป็น sub-task ของตนเอง · agent หลักทำหน้าที่รวบเป็น brief เดียว
Productised
ตั้ง schedule ได้
prompt นี้กลายเป็น scheduled task ที่รันทุก 06:00 น. โดยอัตโนมัติ — mini-app ตัวแรกของท่านถือกำเนิด
สาระสำคัญ (Key Takeaway)
Mini-app ตัวแรกของท่าน = prompt ที่ orchestrate sub-agent แบบขนาน แล้วรวมผลลัพธ์เป็น output เดียว — ขาดเพียง schedule และ delivery channel ก็จะกลายเป็น service ที่สมบูรณ์โดยไม่จำเป็นต้องสร้างขึ้นใหม่จากศูนย์
ทดสอบความเข้าใจ · Quick Check หากให้
agent เดียวอ่านทั้ง 4 CSV ก็ให้ผลลัพธ์เหมือนกัน — เหตุใดต้องแยกเป็น
sub-agent?
3 เหตุผล: (1) Context isolation — sub-agent
แต่ละตัวเห็นเฉพาะข้อมูลที่ตนเองต้องใช้ ไม่ปะปนกันใน context window
(2) Parallel เร็วกว่า serial — 4 sub-task
ที่รันพร้อมกันใช้เวลาเท่ากับ task ที่ช้าที่สุดเพียง 1 task (3)
Prompt เฉพาะทาง — การเปลี่ยน sub A
ไม่ส่งผลกระทบต่อ B/C/D · นี่คือรากฐานของ harness
Session B · Recovery patterns (รูปแบบแก้สถานการณ์) 6 ปัญหาที่เจอบ่อย — และ prompt ที่ใช้แก้ Vibe Coding ไม่ได้ราบรื่นเสมอไป · บางครั้ง AI ปฏิเสธ output ไม่ตรง หรือวนแก้ไม่จบสิ้น · ปัญหาส่วนใหญ่แก้ได้ด้วยการ "ปรับ prompt" ไม่ใช่ "เปลี่ยน tool" · 6 รูปแบบนี้ครอบคลุมประมาณ 80% ของสถานการณ์จริงที่พบเจอ
ปัญหา 1 ผลลัพธ์ไม่ตรง intent (เจตนา) — "ดูเหมือนถูก แต่ไม่ใช่สิ่งที่ต้องการ" อาการ: prompt ระบุไม่ครบถ้วน AI จึงเดาส่วนที่ขาดเอง — บางครั้งเดาถูก บางครั้งไม่
Prompt ที่ใช้แก้: "แสดงตัวอย่าง input → output ที่ concrete (ชัดเจน) 3 ตัวอย่างที่คุณคิดจะ generate · ผมจะยืนยันก่อนคุณเขียน code"
ปัญหา 2 Output ยาวเกินไป — truncated (ถูกตัดทอน) หรือต้อง scroll ยาวมาก อาการ: response ตัดกลางทาง หรือ Claude ขอให้กด "continue" ซ้ำหลายครั้ง
Prompt ที่ใช้แก้: "แสดงเฉพาะ section ที่เปลี่ยน · ใช้ diff format · ไม่ต้องเขียนไฟล์ทั้งหมดใหม่"
ปัญหา 3 แก้ bug หนึ่งแล้วเกิด bug ใหม่ — วนไม่จบสิ้น (infinite loop) อาการ: ผ่านไปแล้ว 4–5 รอบยังไม่จบ AI แก้จุดหนึ่งแต่ทำให้อีกจุดเสีย
Prompt ที่ใช้แก้: "หยุดก่อน · เริ่มใหม่ตั้งแต่ต้น — สร้าง app นี้ใหม่โดยรู้ทุกอย่างที่เราคุยกันมา · ช่วยเขียน prompt ใหม่ให้ผม ตามที่คุณคิดว่าควรจะได้รับตั้งแต่แรก"
ปัญหา 4 Claude ตอบว่า "ทำไม่ได้" หรือถามขอข้อมูลเพิ่มเติมไม่จบ อาการ: refusal (การปฏิเสธ) เนื่องจากเข้าใจว่ามีข้อจำกัด หรือถาม clarifying questions (คำถามเพื่อความชัดเจน) ซ้ำไม่จบ
Prompt ที่ใช้แก้: "ลองทำให้เต็มที่ก่อน · ใช้ assumption (สมมติฐาน) ที่ดีที่สุดกับสิ่งที่ไม่ชัดเจน · ระบุ assumption ที่ใช้ไว้ที่ด้านบน · ผมจะแก้ทีหลังเองหากผิด"
ปัญหา 5 Output ใช้ library / API ที่ไม่มีอยู่จริง — hallucination (การกุข้อมูลขึ้นมา) อาการ: รัน code แล้วเจอ error "module not found" หรือเรียกใช้ function ที่ไม่มีอยู่จริง
Prompt ที่ใช้แก้: "ใช้เฉพาะ library ที่อยู่ใน standard browser API · หากจำเป็นต้อง install อะไร ให้ระบุ ชื่อ + version + คำสั่ง install ไว้ก่อน · error: <paste error>"
ปัญหา 6 App ทำงานได้ แต่ "หน้าตายังไม่เรียบร้อย / ไม่ professional" อาการ: UI (User Interface) ดูเหมือน skeleton (โครงร่างเปล่า ๆ) — ทำงานได้ แต่ผู้ใช้จริงจะไม่อยากใช้
Prompt ที่ใช้แก้: "ทำให้ดูเหมือน product ของ Stripe / Linear / Vercel · ใช้ spacing ให้มากขึ้น typography ชัดเจน สี neutral พร้อม accent เพียง 1 สี · เพิ่ม hover state + micro-interaction"
Meta-rule (กฎสำคัญ) หากวน 3 รอบแล้วยังไม่ดีขึ้น → หยุดทันที และเริ่มต้นใหม่ด้วย prompt ที่ละเอียดกว่าเดิม ไม่ควรแก้ไขซ้ำต่อไปเรื่อย ๆ · context window (หน่วยความจำของการสนทนา) จะเต็มไปด้วย bad attempt (ความพยายามที่ไม่สำเร็จ) จนทำให้คุณภาพถดถอยลง · เริ่มต้นใน chat ใหม่ และระบุให้ชัดเจนว่า "ขอเริ่มใหม่ — ต้องการ ___ โดยมีข้อกำหนดดังนี้ ___"
สาระสำคัญ (Key Takeaway) ทักษะ (skill) ที่แท้จริงของ Vibe Coding คือ "การรู้ตัวว่ากำลังติดขัด แล้วเปลี่ยน strategy (กลยุทธ์) ได้รวดเร็ว" — มิใช่เพียง "เขียน prompt ให้ดีขึ้น" · 6 รูปแบบนี้คือ checklist (รายการตรวจสอบ) ที่หยิบมาใช้ได้ทันทีใน workshop วันนี้ — แนะนำให้บันทึกไว้ใน notes ก่อนเริ่ม Demo
May 2026 · ปีของ Harness
AI Harness — โครงสร้างที่ทำให้โมเดลกลายเป็น Agent
ในปี 2025 หัวข้อสนทนาหลักคือ agent ส่วนในปี 2026
หัวข้อเปลี่ยนเป็น harness — เพราะข้อเท็จจริงคือ
70% ของประสิทธิภาพ agent อยู่นอกตัวโมเดล
ประสิทธิภาพอยู่ที่ harness ซึ่งเป็นชั้น scaffolding
ที่ห่อหุ้มโมเดลไว้ ทำให้สามารถวางแผน เรียกใช้ tool จดจำ
และฟื้นตัวจากข้อผิดพลาดได้
70%
ของประสิทธิภาพ agent อยู่นอก โมเดล
65%
ของ AI failure ในองค์กรเกิดจาก
harness ไม่ใช่โมเดล
80%
ของเวลาทำ agentic AI หมดกับ data eng + governance
(McKinsey)
2–4hr
= minimum viable harness แรก (20–50 บรรทัด)
กายวิภาคของ Harness — 6 ส่วน
6 components ของ harness ที่ห่อหุ้มโมเดล
แผนภาพ hub-and-spoke แสดงโมเดลที่จุดกึ่งกลาง ล้อมรอบด้วย 6 components: Orchestration Loop, Tools, Memory, Context Management, State Persistence, และ Guardrails + Observability · เส้นประรอบนอกแทนขอบเขตของ harness
MODEL
Opus 4.7
01 / LOOP
Orchestration
02 / TOOLS
Read · Write · Call
03 / MEMORY
Short + Long-term
04 / CONTEXT
Management
05 / STATE
Persistence
06 / SAFETY
Guardrails + Obs
เส้นประ = ขอบเขตของ Harness
1
Orchestration Loop
"สมอง" — ตัดสินใจขั้นถัดไป รัน task แล้ววนกลับมาคิดต่อ until
done
2
Tools
ทำอะไรได้บ้าง — อ่าน/เขียนไฟล์, เรียก API, รัน code, ค้น web
3
Memory
จำอะไรระหว่างรัน — short-term ใน context, long-term ในไฟล์/DB
4
Context Management
อะไรเข้า context window — บีบอัด เลือก สรุปก่อนทิ้ง
5
State Persistence
งานที่กินเวลาเป็นชั่วโมง/วัน ข้าม session ต่อจากเดิมได้
6
Guardrails + Observability
กันพัง + เห็นว่าทำงาน — eval, log, kill switch, schema check
4 กลยุทธ์ Context Management (LangChain · 2026)
ภายใต้ component "Context Management" ในตารางด้านบน — อุตสาหกรรมได้สรุปเป็น
4 strategies มาตรฐาน ที่ทุก harness ต้องเลือกใช้ ·
ที่น่าสนใจคือ Demo ทั้ง 3 ของวันนี้ใช้ทั้ง 4 strategies นี้อยู่แล้ว
เพียงแต่ยังไม่ได้ตั้งชื่อ
Write
เขียนออก (Persist)
เก็บ context ไว้ภายนอก context window — file, database, memory store · ดึงกลับมาเมื่อต้องการ
เห็นใน Demo #2: policy markdown file
Select
คัดเลือก (Retrieve)
ดึงเฉพาะส่วนที่เกี่ยวข้องผ่าน RAG / lookup · ไม่ต้องโหลดทั้งหมดเข้า context
เห็นใน ESG Demo: grid factor lookup ตาม region + year
Compress
บีบอัด (Summarize)
สรุป context ที่ยาวก่อนผ่านต่อ · ลด token รักษา signal-to-noise
เห็นใน Demo #3: agent หลักรวบ output ของ sub-agent
Isolate
แยกบริบท (Isolate)
แยก context window ระหว่าง sub-agent · แต่ละตัวเห็นเฉพาะที่ตนเองต้องใช้
เห็นใน Demo #3: sub-agent A/B/C/D อ่านคนละ CSV
Pattern ใหม่จาก Anthropic (เม.ย. 2026) — Three-Agent Harness
Task
Planner
Generator
Evaluator
?
เสร็จ / วน
Planner วางแผน → Generator ทำงาน →
Evaluator ตรวจ — ถ้าไม่ผ่าน วนกลับไป Planner ใหม่ —
ใช้กับงานที่กินเวลาเป็นชั่วโมง/วัน
หลักการสำคัญ (Anthropic Engineering Blog · 2026)
"ทุก component ใน harness
คือสมมติฐานว่าโมเดลยังทำสิ่งนั้นเองไม่ได้
— เมื่อโมเดลมีความสามารถเพิ่มขึ้น component
เหล่านั้นควรถูกถอดออกตามลำดับ — scaffolding
ที่ไม่ถูกถอดออกจะกลายเป็นหนี้ทางเทคนิค"
ตัวอย่างจริง — Opus 4.7 (เม.ย. 2026)
Anthropic เปิดตัว Claude Opus 4.7 พร้อมความสามารถ
self-verification ในระดับโมเดล —
ตรวจ output ของตนเองก่อนรายงานผลกลับ ·
ผลลัพธ์คือ SWE-bench Verified ขยับจาก 80.8% →
87.6% ในการ release เดียว ·
นี่คือสัญญาณว่า
Evaluator role ใน Three-Agent pattern กำลังถูกถอดออกอย่างเป็นรูปธรรม
— Generator + native verification เริ่มเพียงพอสำหรับงานหลายประเภท ·
scaffolding ที่ถอดได้แล้ว ควรถอดในเวลาที่เหมาะสม
การเชื่อมโยงกับ Demo #3
Sub-agent A / B / C / D ใน Demo #3 ประกอบกับ agent หลักที่ทำหน้าที่
orchestrate คือ harness ตัวแรกของท่าน — ประกอบด้วย
orchestration loop, tools (อ่าน CSV), memory (sub-task ส่งผลกลับ),
และ context management (lead agent ทำหน้าที่บีบอัด) ครบ 4 จาก 6
components คงเหลือเพียง state persistence และ guardrails
ที่จะเพิ่มเข้ามาภายหลังตามความจำเป็น
Framework ที่ควรรู้ในปี 2026
Framework
เจ้าของ
เด่นเรื่อง
เหมาะกับ
Claude Agent SDK Anthropic
tool loop, sub-agents, MCP built-in
เริ่มจาก Claude — มี harness พร้อมใช้
Claude Managed Agents
beta
Anthropic
harness ที่ Anthropic host ให้ — ไม่ต้องดูแล infra
SME ที่ไม่มี platform team
LangGraph LangChain
graph-based, explicit control — 87% benchmark
ทีมที่ต้องคุม flow แม่นยำ
CrewAI open source
role-based — 44K GitHub stars, 50% F500
multi-agent ที่บทบาทชัดเจน
OpenAI Agents SDK OpenAI
คู่หูกับโมเดล OpenAI โดยตรง
ทีมที่ใช้ GPT เป็นหลัก
สำหรับ SME — 3 ขั้นเริ่มต้น
เริ่มจากระดับเล็กที่สุด
2–4 ชั่วโมง · 20–50 บรรทัดโค้ด — เพียง orchestration loop กับ
2-3 tools ก็เพียงพอ
ไม่ควรรีบเพิ่มทุก component พร้อมกัน
รัน 50 task จริงก่อนจะเพิ่มสิ่งอื่น
ยังไม่จำเป็นต้องใส่ persistence, observability หรือ guardrails —
รอจนเห็นจุดที่ระบบเริ่มมีปัญหา แล้วจึงเพิ่มทีละชั้น
เพิ่ม component ตามอาการที่พบ
context มีปัญหา → context mgmt · งานระยะยาวล้มเหลว → state
persistence · มี risk → guardrails · vendor หรือ regulator
จะตรวจสอบ → observability
สิ่งที่ควรศึกษาเชิงลึก เทียบกับสิ่งที่เพียงใช้งาน —
durable vs disposable
ศึกษาเชิงลึก (durable):
6 components ข้างต้น เป็น pattern ของ distributed systems
ที่ใช้กันมานานนับสิบปี และจะยังคงเป็นมาตรฐานในปี 2030 ไม่ว่า
Anthropic หรือ OpenAI จะยังคงดำเนินกิจการในรูปแบบใดรับทราบเพื่อใช้งาน (disposable):
Framework table ด้านบน — ประมาณครึ่งหนึ่งจะถูกแทนที่ภายใน 18 เดือน
ควรเลือกเพียง 1 ตัวให้ทีมใช้ แต่ไม่ควรยึดติด
และไม่ควรใช้เป็นเกณฑ์ในการรับบุคลากรใหม่
สาระสำคัญ (Key Takeaway)
70% ของประสิทธิภาพ agent อยู่นอกโมเดล — เริ่มต้น
harness ที่ 20-50 บรรทัด เพิ่ม component
เฉพาะเมื่อพบอาการที่ต้องแก้
ไม่ใช่บรรจุครบทุกองค์ประกอบตั้งแต่ต้น
ทดสอบความเข้าใจ · Quick Check Demo #3
ใช้ harness component ใดไปแล้วบ้าง? ขาดส่วนไหน?
ครบ 4 จาก 6 component — (1) Orchestration loop
ที่ agent หลักสั่งงาน sub-agent (2) Tools คือการอ่าน CSV (3)
Memory คือผลลัพธ์ที่ sub-agent ส่งกลับมา (4) Context management
โดย agent หลักทำหน้าที่บีบอัดและสรุป —
ขาด State persistence (เพราะรันครั้งเดียวเสร็จ)
และ Guardrails (เพราะยังไม่มี business risk) —
เพิ่มเข้ามาเมื่อจะตั้ง schedule รันรายวัน นี่คือหลัก "add by
symptom"
เส้นทางการ productize
จาก Mini-App สู่ Enterprise App
prompt เดิม — เพิ่มความแข็งแรงขึ้นไปตามลำดับ 5 ระดับ — SME ส่วนใหญ่มักหยุดอยู่ที่ระดับ 2 และพลาดผล compound (ผลทบต้น) ที่จะเกิดในระดับสูงขึ้น
ระดับ
หน้าตา
ใครรัน
เพิ่มอะไร
1 · Prompt copy-paste ในแชท
1 คน
ไม่มี — แค่คำพูด
2 · Skill บันทึกเป็น skill ใช้ซ้ำได้
ทั้งทีม
คำสั่ง + ตัวอย่าง input/output
3 · Mini-App Skill + schedule + connector
หลายทีม
MCP connectors, schedule, ช่องทาง output
4 · Internal Service มี version, monitor, log
ทั้งองค์กร
RBAC, audit log, eval suite, on-call
5 · Enterprise App customer-facing หรือรายงานบอร์ด
ลูกค้าภายนอก / regulator
SLA, compliance (SOC2/ISO), red-team, change mgmt
แต่ละระดับมีการเพิ่ม 3 องค์ประกอบ
Boundaries
กำหนดผู้ที่สามารถรันได้ ขอบเขตข้อมูลที่ใช้
และข้อจำกัดที่ต้องปฏิบัติตาม
Memory
กำหนดข้อมูลที่ต้องจดจำระหว่างการรัน และข้อมูลที่ต้องลบทิ้ง
Observability
วิธีการตรวจสอบว่าระบบยังทำงานปกติ
และการแจ้งเตือนเมื่อเกิดความผิดปกติ
Crawl → Walk → Run — กรอบจาก Microsoft ที่ map ตรงกับ 5 stage
Microsoft (2023) ได้นำเสนอกรอบ Crawl-Walk-Run สำหรับการเพิ่มระดับ automation ของ AI ในผลิตภัณฑ์อย่างค่อยเป็นค่อยไป — มีแนวคิดสอดคล้องกับ 5 stage ของเรา แต่ย่นให้เหลือเพียง 3 จังหวะใหญ่ที่ผู้บริหารจดจำได้ง่าย
Crawl
คนต้องอยู่ใน loop เสมอ
AI ทำหน้าที่นำเสนอ ส่วนบุคคลเป็นผู้ตัดสินใจและกดส่งในทุกครั้ง · สอดคล้องกับ Stage 1–2 ของเรา
Walk
AI ทำงานกับ user ภายใน
AI สื่อสารกับพนักงานในองค์กรได้โดยตรง พร้อมด้วย audit, eval และ rollback ที่ใช้งานได้ทันที · สอดคล้องกับ Stage 3–4 ของเรา
Run
AI ทำงานกับ user ภายนอก
AI สื่อสารกับลูกค้า · regulator · ตลาดได้โดยตรง พร้อมด้วย SLA และ compliance ที่ครบถ้วน · สอดคล้องกับ Stage 5 ของเรา
ทำไมต้อง "เริ่มภายในก่อน" — ข้อมูลจริงจากตลาด
รายงาน a16z Growth (2024) ได้เก็บข้อมูลจากองค์กรที่ทดลองใช้ LLM — สัดส่วนที่ deploy ขึ้น production จริงนั้นต่างกันอย่างชัดเจน ระหว่างงาน internal-facing กับ external-facing · ตัวเลขนี้คือเหตุผลที่ deck ฉบับนี้แนะนำให้ SME เริ่มจาก Demo #2 (PR Triage ภายในองค์กร) ก่อน Demo #3
62%
ขององค์กร deploy text summarization ภายใน ขึ้น production ได้
60%
deploy enterprise knowledge management ภายในขึ้น production
39%
deploy chatbot ที่หันออกหาลูกค้า ขึ้น production ได้
39%
deploy recommendation algorithm ภายนอกขึ้น production ได้
อ้างอิง: a16z Growth, The 2024 Enterprise Generative AI Report · งาน internal-facing มี risk ต่ำกว่า — เนื่องจาก bug ของ AI ตกอยู่กับพนักงาน มิใช่ลูกค้า · ควรใช้ช่วงเวลานี้สร้าง AI engineering muscle ขององค์กรให้แข็งแรง ก่อนปล่อยสู่ภายนอก
3 องค์ประกอบที่เพิ่มในแต่ละ stage คือ 3 component ของ harness ที่หนาขึ้นตามลำดับ — Stage 4-5 มี harness ครบทั้ง 6 ส่วน · ส่วน Stage 1-2 มีเพียง orchestration loop และ tools ก็เพียงพอแล้ว
สาระสำคัญ (Key Takeaway)
Prompt เดิมคงอยู่ตลอด — สิ่งที่หนาขึ้นตามลำดับ 5 stage คือ Boundaries + Memory + Observability ที่ห่อหุ้มอยู่รอบ ๆ ไม่ใช่ logic ใหม่ · จึงสามารถยกระดับขึ้น stage ถัดไปได้โดยไม่ต้อง rewrite ใหม่ทั้งหมด
ทดสอบความเข้าใจ · Quick Check Stage 3
(Mini-App) ต่างจาก Stage 2 (Skill) อย่างไรในแง่ของ "ผู้เรียกใช้"?
Stage 2 : ผู้ใช้งานคือทีมของตนเอง
รันด้วยตนเองบนเครื่องของตน · Stage 3 :
หลายทีมสามารถใช้งานได้ มี schedule รันอัตโนมัติ มี output channel
(email/Slack) — กล่าวคือ Stage 3 มี
"ผู้เรียกใช้ที่ไม่ใช่บุคคล" แล้ว
นี่คือจุดที่ต้องเริ่มพิจารณาเรื่อง monitoring และ error handling
บันได Maturity
SME → PCL: เส้นทาง scale up ด้วย AI
จากร้าน 5 คน สู่บริษัทมหาชน (PCL) ส่วนใหญ่คือเรื่อง
กระบวนการ — และ Claude ย่อส่วนที่เคยต้องเพิ่ม headcount
Stage 1 · Startup
รอด
เจ้าของทำทุกอย่าง — AI = productivity ส่วนตัว (ร่างอีเมล
สรุปโน้ต เขียน copy)
Stage 2 · SME
มาตรฐาน
งานซ้ำเริ่มเยอะ — เขียน SOP เป็น BPMN, automate ด้วย Claude
skill ประหยัด 1 FTE/process
Stage 3 · Mid-Market
Scale
หลายทีม หลาย skill — MCP เข้า ERP/CRM — daily ops dashboard —
cross-team workflow
Stage 4 · PCL
Govern
Audit log, RBAC, eval, vendor risk พร้อม regulator — AI เป็น
"controlled function" มีเจ้าของ มี SLA
แต่ละขั้นเพิ่มอะไร
มิติ
SME
Mid-Market
PCL
เอกสาร process
อยู่ในหัวคน
มี BPMN library
มี version + audit ได้
Identity
login ใช้ร่วมกัน
SSO
SSO + RBAC + JIT access
Data
Spreadsheet
ERP/CRM ผ่าน MCP
Data warehouse + lineage
การใช้ AI
prompt ส่วนตัว
shared skill
governed service + eval
Risk
ผู้บริหารตัดสินด้วยประสบการณ์
checklist
risk register + DR plan
ESG disclosure
ไม่เป็นทางการ
GRI-light · เริ่ม Scope 1-2
SET One Report + ISSB ครบถ้วน
หลักการสำคัญ
SME ที่สร้างพื้นฐาน BPMN และ Skill ไว้ก่อน การ
scale — จะไม่จำเป็นต้อง re-platform เมื่อองค์กรเติบโตขึ้น
เพราะกระบวนการที่วาดในวันนี้คือกระบวนการเดียวกันกับที่จะใช้ govern
เมื่อเป็น PCL เพียงแต่จะมีการเพิ่ม control
ในระดับที่เหมาะสมตามลำดับ
สาระสำคัญ (Key Takeaway)
SME ที่ลงทุนใน BPMN + Skill ตั้งแต่ stage 2 =
ไม่จำเป็นต้อง re-platform เมื่อเติบโตเป็น PCL —
เพราะกระบวนการเดิมเพียงเพิ่ม control ทีละชั้น มิใช่การสร้าง stack
ขึ้นใหม่
ทดสอบความเข้าใจ · Quick Check ในตาราง
SME → PCL "ผู้บริหารตัดสินด้วยประสบการณ์" เปลี่ยนเป็นอะไรใน PCL?
และทำไม?
เปลี่ยนเป็น "risk register + DR plan" — เพราะ
regulator/board ต้องการเห็นว่ามี
กระบวนการที่เป็นทางการ มิใช่ความสามารถส่วนบุคคล —
หากผู้บริหารท่านนั้นพ้นจากตำแหน่ง
องค์กรยังคงต้องตัดสินใจได้อย่างเดิม นี่คือหัวใจของ governance:
เปลี่ยนความรู้ในตัวบุคคลให้กลายเป็น process ที่เป็นรูปธรรม
Investor-readable · Regulator-defensible
ESG — เมื่อ AI ช่วยให้การรายงานเป็นไปได้จริง และเมื่อตัว AI เองก็ต้องได้รับการกำกับเช่นกัน
เมื่อองค์กรขยายขนาดจาก SME สู่ PCL การรายงาน ESG จะกลายเป็นข้อกำหนดที่หลีกเลี่ยงไม่ได้ ครอบคลุมตั้งแต่ SET One Report 56-1 , GRI, SASB, TCFD ไปจนถึง ISSB · รอบการรายงานที่ทีมการเงินและทีมความยั่งยืนเคยใช้เวลาเป็นเดือน AI ช่วยลดลงเหลือเพียงระดับวันได้ — ในทางกลับกัน ตัว AI เองก็เป็นพื้นที่ใหม่ที่ต้องอยู่ภายใต้การ govern (กำกับดูแล) ทั้งในด้านพลังงาน, bias และ accountability
E · Environmental
การรายงานด้านสิ่งแวดล้อม
ข้อกำหนดของ PCL: Scope 1/2/3 emission,
climate-related risk ตาม TCFD
Claude ช่วยได้: ดึงข้อมูล emission จาก invoice และ utility bill · normalize หน่วยให้สอดคล้องกัน · ร่างคำบรรยายเชิง narrative
Use case: คำนวณ Scope 2 รายไตรมาสจาก electricity bill — ลดเวลาจาก 15 ชั่วโมงเหลือ 30 นาที
AI footprint ขององค์กรเอง: เลือก model ขนาดเล็ก (เช่น Haiku)
สำหรับงานที่ไม่ต้องการความซับซ้อน ลดทั้งต้นทุนและการปล่อยคาร์บอน
S · Social
การรายงานด้านสังคม
ข้อกำหนดของ PCL: human capital, diversity,
supplier code of conduct
Claude ช่วยได้: สังเคราะห์ข้อมูล employee survey · คัดกรอง supplier attestation · ร่างหัวข้อ DEI
Use case: ประมวลผล supplier compliance attestation 1,000 รายภายในวันเดียว เทียบกับการทำ manual ที่ทำได้เพียงประมาณ 50 รายต่อวัน
AI ขององค์กรเอง: bias audit, การจัด accessibility ของ output,
และ human-in-loop สำหรับการตัดสินใจที่กระทบบุคคลโดยตรง (เช่น
hiring, lending)
G · Governance
การกำกับดูแล
ข้อกำหนดของ PCL: board oversight สำหรับ risk
ทั้งหมด (รวม AI risk), audit committee, whistleblower channel
Claude ช่วยได้: สรุป board report · ร่าง policy document · monitor compliance อย่างต่อเนื่อง
Use case: continuous monitoring การละเมิด expense policy — แจ้งเตือนทันทีที่ตรวจพบ ลดเวลา detection จากระดับเดือนเหลือชั่วโมง
AI ขององค์กรเอง: model card, eval log, RBAC —
เชื่อมโยงโดยตรงกับทั้ง 6 component ของ
AI Harness
บริบทประเทศไทย — กรอบที่ต้องทำความเข้าใจ
กรอบ
ผู้บังคับใช้
เนื้อหา
สถานะปี 2026
One Report 56-1 SET / SEC
การเปิดเผยข้อมูลประจำปีของบริษัทจดทะเบียน
บังคับใช้
SET ESG Ratings SET
การจัดอันดับ ESG ของบริษัทจดทะเบียน (เดิมคือ THSI)
บังคับใช้
ISSB IFRS S1/S2 IASB / TFAC
มาตรฐาน sustainability disclosure ระดับสากล
SET50 บังคับเริ่มปี 2026 — climate-first, Scope 3 deferred, S1+S2 ต้อง limited assurance
TCFD FSB / SET
climate-related financial disclosure
บังคับใช้สำหรับ Top 100
GRI Standards GRI
มาตรฐานสากลสำหรับการรายงานความยั่งยืน
ใช้แบบสมัครใจ
SET50 — กำหนดการที่ต้องทราบในปี 2026
ปี 2026 เป็นปีแรกที่ SET50 ต้อง comply อย่างเป็นทางการ
ตามกรอบ IFRS S1 + S2 — โดย Thai SEC เผยแพร่
"ISSB Roadmap" เพื่อ phase-in การ disclose
เปลี่ยนจาก "comply or explain" →
mandatory regime ·
Transition reliefs:
ปีแรกรายงาน climate-first (S2 ก่อน S1),
Scope 3 ได้รับการเลื่อนเวลา,
Scope 1+2 ต้องผ่าน limited assurance
ตามมาตรฐานสากล ·
บริษัทนอก SET50 ยังใช้ comply-or-explain ก่อน
แต่กรอบจะขยายต่อในปีถัดไป
การเชื่อมโยงกับ Maturity Ladder
Stage 1-2 · SME
AI เตรียมความพร้อม
ใช้ AI รวบรวมข้อมูล ESG เบื้องต้น ร่างคำบรรยาย
และทำความเข้าใจกรอบที่จะต้องปฏิบัติตามในอนาคต
Stage 3 · Mid-Market
AI รัน Continuous ESG
เชื่อมต่อ connector กับ utility provider, HR system และ supplier
portal — เก็บข้อมูลแบบต่อเนื่อง ไม่ใช่การรวบรวมรายไตรมาส
Stage 4 · PCL
AI ใน Governance Loop
AI เป็นส่วนหนึ่งของ governance พร้อม audit trail ครบถ้วน
สามารถรายงานต่อ board และ regulator ได้โดยตรง
หลักการสำคัญ — ESG ที่ future-proof
กรอบ ESG มีการเปลี่ยนแปลงเสมอ (GRI 2021 → 2025, ISSB อยู่ในช่วง
transition) แต่
ESG data และ process ที่องค์กรสร้างถือเป็น durable
— หากเก็บข้อมูล emission ในรูปแบบที่มีโครงสร้างชัดเจน
ไม่ว่ากรอบจะเปลี่ยนเป็นแบบใด ก็สามารถนำมา re-format ได้ ดู
Durable vs Disposable ประกอบ
สาระสำคัญ (Key Takeaway)
AI ทำให้ ESG reporting เปลี่ยนจาก "ภาระประจำปีที่ใช้ทรัพยากรมหาศาล" → "การรายงานต่อเนื่อง (continuous) ทุกไตรมาส" — ในขณะเดียวกัน ตัว AI เองคือ governance object ตัวใหม่ที่ต้องบริหารควบคู่กันไปด้วย
ทดสอบความเข้าใจ · Quick Check Scope 1,
2, 3 emission ต่างกันอย่างไร? AI
ช่วยตรงไหนได้มากที่สุดในเบื้องต้น?
Scope 1 = การปล่อยโดยตรง (โรงงาน, รถของบริษัท) ·
Scope 2 = ไฟฟ้าที่ซื้อมาใช้ ·
Scope 3 = ทั้ง supply chain ต้นน้ำและปลายน้ำ —
AI สร้างประโยชน์ให้ Scope 2 ได้มากที่สุดในช่วงเริ่มต้น
เพราะ (1) data มี structure (utility bill) (2) grid factor เป็น
public data ที่หาได้ (3) สามารถ automate แบบ end-to-end
ได้ภายในไตรมาสแรก — Scope 3 มีความซับซ้อนสูงกว่ามาก
ควรดำเนินการหลังจาก Scope 2 มีความเสถียรแล้ว
E
ESG Hands-on · ~35 นาที
Scope 2 Quarterly Report จาก Utility Bills
สถานการณ์
ในทุกการปิดไตรมาส ทีมความยั่งยืนต้องคำนวณ Scope 2 emission (purchased electricity) สำหรับทุก facility และร่างหัวข้อสำหรับ board report · ขั้นตอนแบบ manual คือ: download bill ทีละใบ extract kWh คูณด้วย grid emission factor แล้ว aggregate ตาม facility ก่อนเขียนคำบรรยาย — โดยรวมใช้เวลา 15+ ชั่วโมงต่อไตรมาส
ข้อมูลตัวอย่าง
24 utility bills (4 facility × 6 เดือน · Q4 2025 + Q1 2026) · 4 facility กระจายอยู่ใน TH และ VN · grid factor อ้างอิงจาก TGO และ IEA · มี anomaly 1 จุดที่ AI ต้องตรวจจับให้ได้
BPMN — multi-source ESG calculation
Bills เข้า
Match facility
Lookup grid factor
คำนวณ CO2e
∑
ตรวจ anomaly
รายงาน + narrative
3 sources · 4 ขั้นตอน · output 2 รูปแบบ (CSV ตัวเลข + narrative
สำหรับ board)
รัน demo — prompt
Prompt เขียนเป็นภาษาอังกฤษเพื่อความแม่นยำของ output
Prompt
Copy
You are our sustainability analyst. Produce a Q1 2026 Scope 2 emissions
report from the three CSVs in sample_data/.
For each utility bill:
1) Join to 04_facility_master.csv on facility_id to get region.
2) Look up the correct grid factor in 04_grid_factors.csv by region AND
year (use the year of billing_period_end).
3) Compute kgCO2e = kwh_consumed * kgco2e_per_kwh. Convert to tCO2e.
Then aggregate:
- Q1 2026 total tCO2e (Jan + Feb + Mar 2026)
- By facility for Q1 2026
- Q1 2026 vs Q4 2025 change (% and absolute tCO2e)
- Intensity: tCO2e per headcount and per sqm, by facility
- Flag any month where a facility's kWh deviated 20% from its 3-month
trailing average — these may indicate equipment failure or data error
Output two artefacts:
A) Decision table (CSV): facility | period | tCO2e | vs prior | flag
B) Narrative for board report (~250 words, neutral tone): headline number,
drivers of change, anomalies investigated, recommended next steps.
Cite the grid factor source for each region used.
สิ่งที่ผู้เข้าร่วมควรสังเกต
การ join ข้ามไฟล์
Claude เชื่อมข้อมูล 3 ไฟล์โดยอัตโนมัติด้วย key ที่กำหนดไว้ — ไม่ต้องเขียน SQL หรือ Python แม้แต่บรรทัดเดียว
การคำนวณตามมาตรฐาน
การเลือกใช้ grid factor ที่ถูกต้องตามภูมิภาคและปี เป็นจุดที่ auditor จะตรวจสอบเสมอ — Claude จะอ้างอิง source ให้ทุกครั้งโดยอัตโนมัติ
การตรวจจับ anomaly
Spike ที่ใส่ไว้ใน Rayong Factory เดือนมีนาคมควรถูก flag — เราฝึก ground prompt ให้ตรวจตามเกณฑ์ "เกินค่าเฉลี่ย 20%" แทนที่จะให้โมเดล "นึกเอง"
Output 2 รูปแบบในการรันครั้งเดียว
ตัวเลขสำหรับนำเข้าระบบ + คำบรรยายสำหรับ board — แบ่งแยกออกจากกันอย่างชัดเจน ไม่ปะปนกัน
การเชื่อมโยงกับสไลด์อื่น
Pattern
คล้าย Demo #2
Multi-source + policy reference (ในที่นี้คือ grid factor) + decision table — ใช้ pattern เดียวกันกับ PR approval ใน Demo #2
Harness
ใช้ 4 จาก 6 components
orchestration loop, tools (CSV reader), memory (ระหว่างขั้น) และ context management — ขาดเพียง state persistence และ guardrails ที่จะเพิ่มเมื่อจะตั้งให้รันรายเดือนอัตโนมัติ
Audit-ready
BPMN + run log = หลักฐาน
เมื่อ auditor ถาม "ทำไม Q1 2026 ได้ตัวเลขนี้?" — run log จะมีทุกขั้นตอนการคำนวณพร้อม source citation ให้ตอบได้ทันที
สาระสำคัญ (Key Takeaway)
Data layer (CSV) แยกออกจาก logic layer (prompt) — แก้ไข grid factor ในไฟล์ → ตัวเลขจะเปลี่ยนทันทีโดยที่ prompt ไม่จำเป็นต้องปรับ · ใช้หลักการเดียวกับ Demo #2 (policy file) เพียงเปลี่ยนชั้น data เท่านั้น
ทดสอบความเข้าใจ · Quick Check ทำไมต้องเก็บ grid factor เป็นไฟล์แยก แทนที่จะใส่ตัวเลขลงในตัว
prompt?
3 เหตุผล: (1) Factor มีการเปลี่ยนแปลงทุกปี ตาม TGO/IEA — ทีม sustainability สามารถแก้ไขไฟล์ได้ด้วยตนเอง โดยไม่ต้องขอความช่วยเหลือจาก engineer · (2) แต่ละ region/year ใช้ factor ที่แตกต่างกัน — ตารางอ่านง่ายกว่า if-else ที่ฝังอยู่ใน prompt มาก · (3) Auditor ต้องการเห็น "source ของแต่ละค่า" อย่างตรงไปตรงมา — CSV ตอบโจทย์ได้ดีกว่า prompt blob ที่ผสมข้อมูลเข้ากับ logic อย่างชัดเจน
Future-proof playbook
อะไรอยู่ยง อะไรเปลี่ยน — ลงทุนถูกที่
ในระยะ 3 ปีข้างหน้า โมเดลจะมีการเปลี่ยนรุ่น framework จะเกิดใหม่
และราคาจะปรับลดลง — อย่างไรก็ตาม บางองค์ประกอบจะยังคงอยู่ —
หลักการของการ scale ที่ยั่งยืนคือ
"ลงทุนเฉพาะองค์ประกอบที่มีอายุการใช้งานยาว" และ
"ไม่ยึดติดกับองค์ประกอบที่จะเปลี่ยนแปลง"
Durable
ลงทุนหนัก · ใช้ได้ 5-10 ปี
องค์ประกอบที่มีอายุการใช้งานยาว
เครื่องมือเปลี่ยน แต่องค์ประกอบเหล่านี้ยังคงใช้งานได้
Process maps (BPMN)
ISO standard ตั้งแต่ 2013 — ใช้กันจริงมา 20 ปี
Data schemas & lineage
ข้อมูลคุณอยู่นานกว่า AI ทุกตัว
Compliance & audit practices
กฎหมายไม่เปลี่ยนตามโมเดล
Eval discipline
การวัดคุณภาพเป็นวิทยาศาสตร์ ไม่ขึ้นกับเครื่องมือ
Human-in-loop policy
risk model ขององค์กรท่าน — ไม่เปลี่ยนแปลงแม้โมเดลจะฉลาดขึ้น
Skill abstractions
"ทีมรู้วิธีทำ X" — ไม่ใช่ "ทีมใช้เครื่องมือ Y เป็น"
Harness components (6 ส่วน)
orchestration, tools, memory, context, state, guardrails —
pattern ทั่วไปของ distributed systems
ESG metric definitions & data lineage
ข้อมูล emission และ supply chain ขององค์กรอยู่นานกว่ากรอบ
ESG ทุกฉบับ
Disposable
ปล่อยหลวม · 6-18 เดือนจะเปลี่ยน
องค์ประกอบที่จะเปลี่ยนแปลง
ไม่ควรยึดติด ควรเตรียมการ refactor ไว้เสมอ
โมเดลเฉพาะรุ่น
Opus → Sonnet → อะไรก็ตามใน 2027 — ทุก 6
เดือนมีรุ่นใหม่
Framework เฉพาะ
LangGraph, CrewAI, Strands — Wright's law กับ tooling
Prompt ที่จูนกับโมเดลเฉพาะ
เตรียมใจ refactor ทุกครั้งที่ upgrade โมเดล
โครงสร้างราคา
จะลดลงเรื่อยๆ (Devin: 500$ → 20$/เดือน ใน 1 ปี)
UI convention
chat → agent → ? — อย่า hardcode flow กับ UI ใดๆ
Connector เฉพาะ vendor
ใช้ MCP มาตรฐานเสมอ — vendor SDK เปลี่ยนทุกปี
Stat / benchmark ตัวเลข
"87% benchmark" จะเปลี่ยนเมื่อโมเดลใหม่ออก —
ไม่ควรอ้างอิงในสัญญา
ESG framework version เฉพาะ
GRI 2021 → 2025 · ISSB กำลัง transition · SET ปรับ rating
ทุกปี — เก็บข้อมูลให้ structured แล้ว re-format
ตามกรอบ
หลักการสำหรับการสร้างที่ Future-proof
"หากเลือกที่จะบันทึกและรักษาไว้ ควรมีอายุการใช้งานข้าม model
upgrade อย่างน้อย 3 รุ่น — หากไม่เป็นเช่นนั้น
ไม่ควรบันทึก ไม่ควรฝึกอบรม
และไม่ควรรับบุคลากรใหม่บนพื้นฐานสิ่งเหล่านั้น"
การประยุกต์ใช้ใน workshop นี้
Disposable
รับทราบเพื่อใช้งาน
Framework table · ตัวเลข benchmark · ชื่อโมเดลเฉพาะรุ่น ·
ตัวเลขราคา — ทบทวนเพื่อเข้าใจ ไม่จำเป็นต้องจดจำในรายละเอียด
Action
สำหรับสัปดาห์หน้า
เมื่อเลือก vendor ให้ตั้งคำถามว่า "หากเปลี่ยน vendor
ในวันรุ่งขึ้น องค์กรจะสูญเสียอะไรบ้าง?" — คำตอบที่พึงประสงค์:
สูญเสียเฉพาะสิ่งที่จัดเป็น disposable
จาก Durability สู่ Defensibility — 3 moat ของ AI product
Durable vs Disposable ตอบคำถามว่า "ควรลงทุนตรงจุดใด" — แต่ยังมีอีกคำถามที่สำคัญไม่แพ้กัน คือ "คู่แข่งจะสามารถลอกเลียนเราได้หรือไม่?" · Chip Huyen (AI Engineering , 2025) สรุปไว้ว่าในยุค foundation model มี competitive advantage เพียง 3 ประเภท เท่านั้น — และ 2 ใน 3 ประเภทนั้น ไม่ใช่ ของ SME
Moat 1 · เคยใช่ · ปัจจุบันไม่ใช่
Technology
ในอดีต: ทีมใดฝึก model ได้ดีกว่าย่อมเป็นผู้ชนะ · ปัจจุบัน: foundation model ที่ดีที่สุดเปิดให้ทุกคนใช้ผ่าน API · เทคโนโลยีจึงกลายเป็น commodity — แทบทุกทีมเข้าถึง Claude / GPT / Gemini ตัวเดียวกันได้
คำเตือน: หากกลยุทธ์ขององค์กรท่านคือเพียง "เราใช้ Claude" — นั่นมิใช่ moat
Moat 2 · เป็นของรายใหญ่
Distribution
ความสามารถในการนำ product ไปอยู่ต่อหน้าผู้ใช้จำนวนมาก · เป็นของ Google, Microsoft, Apple และ Meta — บริษัทที่อยู่ใน device / browser / OS ของผู้ใช้อยู่ก่อนแล้ว · SME ไม่สามารถแข่งทาง distribution กับยักษ์ใหญ่เหล่านี้โดยตรงได้
คำถามทดสอบ: "product นี้จะเป็น feature ของ Google Docs ภายใน 12 เดือนได้หรือไม่?"
Moat 3 · ของ SME
Data + Workflow ในมือ
ข้อมูลภายในขององค์กร + workflow เฉพาะของอุตสาหกรรม + ความสัมพันธ์กับลูกค้า · นี่คือ moat ที่ SME สามารถสร้างได้ — ยักษ์ใหญ่ไม่มีข้อมูลของลูกค้าท่าน และไม่เข้าใจ workflow ของอุตสาหกรรมเฉพาะของท่าน
Action: จัดเก็บ data ให้เป็นระเบียบตั้งแต่ Demo แรก — usage log, feedback และ error case — เพื่อสร้าง data flywheel ของท่านเอง
คำถามเตือนใจที่ต้องตอบให้ได้ก่อนสร้าง
"หาก Google / Microsoft / Apple มอบหมาย engineer จำนวน 3 คน ใช้เวลา 2 สัปดาห์ ในการสร้าง product นี้เลียนแบบ พวกเขาจะทำได้หรือไม่?" · หากคำตอบคือ "ได้" — moat ที่แท้จริงของท่านต้องอยู่นอกตัว product · นั่นคือ (ก) data ที่สะสมไปก่อนคนอื่น · (ข) ความเข้าใจ workflow เฉพาะทางที่ยักษ์ใหญ่ไม่มีเวลาสนใจ · หรือ (ค) ความสัมพันธ์กับลูกค้าที่ลอกเลียนได้ยาก
สาระสำคัญ (Key Takeaway)
ลงทุนเชิงลึก ใน process / skill / data /
compliance (durable) — คงไว้ซึ่งความยืดหยุ่น ในชั้น
model version / framework / vendor SDK (disposable) · ในระดับธุรกิจ moat ที่ SME สามารถสร้างได้ คือ data + workflow + ความสัมพันธ์ลูกค้า มิใช่เพียง "เราใช้ AI" · คำถามทดสอบ:
"หากเปลี่ยน vendor ในวันพรุ่งนี้ องค์กรจะสูญเสียสิ่งใดบ้าง?"
ทดสอบความเข้าใจ · Quick Check Prompt
ที่จูนกับโมเดลเฉพาะ — durable หรือ disposable?
แล้วต้องเก็บอย่างไรให้ปลอดภัย?
Disposable — เพราะ prompt จำเป็นต้อง refactor
ทุกครั้งที่มีการ upgrade โมเดล · วิธีจัดเก็บ: บันทึกใน skill repo,
ระบุ tag ด้วยชื่อโมเดลที่ใช้,
และจัดเก็บ eval set ไว้ควบคู่กัน — เมื่อย้ายโมเดล
รัน eval เพื่อตรวจสอบว่ายังให้ผลลัพธ์ที่ถูกต้อง · สิ่งที่ "อยู่ยง"
คือ eval set มิใช่ prompt —
นี่คือสินทรัพย์ที่ใช้ได้ข้าม model upgrade
เริ่มต้นในเช้าวันจันทร์
Starter Pack — ภารกิจประจำสัปดาห์
5 ขั้นตอนรูปธรรม แต่ละขั้นใช้เวลาไม่เกิน 90 นาที —
เมื่อดำเนินการครบทุกขั้น องค์กรจะอยู่ที่ Stage 2 ได้ภายในสิ้นสัปดาห์
ก่อนเริ่ม Step 1 — ตอบตนเองให้ชัดเจนก่อนว่า เหตุใดจึงต้องทำ
Chip Huyen (AI Engineering , 2025) ได้สรุปไว้ว่าโปรเจกต์ AI ที่ทีมเลือกดำเนินการนั้นมีเพียง 3 เหตุผลที่สมเหตุสมผล · ก่อนเลือก process ใน Step 1 ให้ระบุให้ชัดเจนว่า project ที่กำลังจะเริ่มอยู่ในกลุ่มใด — เพื่อให้ระดับความเร่งด่วน งบประมาณ และ tolerance ต่อความล้มเหลว สอดคล้องกับเหตุผลที่แท้จริง
เหตุผล 1 · เร่งด่วนที่สุด
หากไม่ทำ คู่แข่งที่ใช้ AI อาจทำให้เราล้าสมัย
AI ถือเป็น existential threat ต่อธุรกิจ · เห็นได้ชัดเจนในงานประเภท document processing, financial analysis, insurance และ advertising · ตัวอย่างเชิงประจักษ์: Kodak, Blockbuster, BlackBerry — บริษัทที่ตอบสนองล่าช้าจนเกินไป
7% ของผู้บริหารใน Gartner 2023 อยู่ในกลุ่มนี้ · ลงทุนเต็มที่ · highest priority
เหตุผล 2 · พบบ่อยที่สุด
หากไม่ทำ จะเสียโอกาสเพิ่ม productivity และกำไร
AI ช่วยลดต้นทุน · เพิ่ม margin · ทำให้ user acquisition มีต้นทุนต่ำลง · เพิ่ม customer retention · ครอบคลุมตั้งแต่ sales lead, internal communication ไปจนถึง market research
SME ส่วนใหญ่อยู่ในกลุ่มนี้ · ลงทุนระดับกลาง · มี ROI ชัดเจน
เหตุผล 3 · เผื่ออนาคต
ยังไม่แน่ใจว่า AI จะเข้าตรงไหน — แต่ไม่อยากตกขบวน
ไม่ควรไล่ตามทุก hype — แต่หลายบริษัทล้มไปเพราะรอนานเกินไป · การลงทุนเพื่อทำความเข้าใจว่า AI จะส่งผลกระทบต่อธุรกิจอย่างไรนั้น เป็นการลงทุนที่ถูกต้อง หากองค์กรมีกำลังพอ
เหมาะกับ R&D budget · ลงทุนน้อย · tolerance ต่อความล้มเหลวสูง
คำเตือน: หากยังไม่สามารถระบุได้ว่า project อยู่ในกลุ่มใด — ยังไม่ควรเริ่มต้น · เพราะจะส่งผลให้งบประมาณบานปลาย timeline เลื่อนออกไป และทีมหมดแรงในช่วง Last Mile (ดู FAQ — Last Mile trap )
เลือก process เพียงหนึ่งรายการ
เลือกงานที่ทำซ้ำอย่างน้อยสัปดาห์ละครั้ง
และมีการย้ายข้อมูลระหว่างที่ต่างๆ — บันทึกชื่อลงใน sticky note
ไม่ควรเลือกมากกว่าหนึ่ง
วาด BPMN จำนวน 5 กล่อง
Event → Task → Gateway → Task → Event — บนกระดาน บนกระดาษ หรือใน
Figma ล้วนใช้ได้ทั้งสิ้น เครื่องมือมิใช่ประเด็นสำคัญ
การวาดด้วยตนเองคือเนื้องาน
เชื่อมต่อแหล่งข้อมูล 1 แหล่ง
ติดตั้ง MCP connector 1 ตัว (Drive, Sheet หรือ ERP ขององค์กร)
และตรวจสอบให้แน่ใจว่า Claude สามารถอ่านข้อมูลได้
ทดสอบรัน 5 ครั้งใน shadow mode
ให้ Claude ทำงานคู่ขนานกับบุคลากร แล้วเปรียบเทียบผลลัพธ์ —
ขั้นตอนนี้คือ eval ในระดับเบื้องต้นที่นำไปใช้ได้จริง
บันทึกเป็น Skill และตั้ง schedule
เมื่อผลการเปรียบเทียบ 5 ครั้งอยู่ในระดับที่ยอมรับได้ ให้บันทึก
prompt เป็น skill จากนั้นกำหนด schedule หรือสร้าง trigger
คำสั่งเดียวให้ทีมใช้
สิ่งที่นำกลับไปจากวันนี้
เด็คประกอบ workshop
นำกลับมาทบทวนได้ทุกครั้งที่มีการ onboarding บุคลากรใหม่
Sample data set
8 ไฟล์ใน sample_data/ — นำกลับไปทดลองรัน demo
ด้วยตนเองได้
BPMN จำนวน 1 รูป
ของ process ขององค์กรเอง — นำกลับมาทบทวนในครั้งต่อไป
ขอบฟ้าถัดไป — Beyond Starter Pack
เมื่อ Starter Pack 5 ขั้นเสร็จและมี process ที่ stable แล้ว 3–5 ตัว
(โดยทั่วไป 60–90 วัน) — เส้นทางขยายผลถัดไปคือ 4 ทิศทางนี้
Stage 3 ขึ้นไป
Claude Projects
Context ที่ persist ข้าม conversation · upload skill repo + reference docs ครั้งเดียว ใช้ได้ทุก session · เหมาะกับงานที่ต้อง onboard ความรู้บริษัทเข้า Claude
Stage 3-4
Claude Agent SDK
Custom harness ตั้งแต่ 20-50 บรรทัด · เริ่มจาก scripted skill → mini-app → service · เป็น path มาตรฐานเมื่อ workflow ใหญ่กว่า 1 prompt
Stage 4+
Computer Use
Claude ควบคุม browser โดยตรง — automation ข้าม app ที่ไม่มี API (เช่น dashboards เก่า, vendor portal) · เปลี่ยน "ทำไม่ได้" เป็น "ทำได้แต่ต้องดูแล"
Stage 4 บังคับ
Eval set + Observability
เมื่อ workflow มี SLA หรือ regulator จะตรวจ — eval set 20-50 คำถามที่รันทุก deploy · plus run log + alert · นี่คือ "durable" ที่อยู่ข้าม model upgrade
ไม่ต้องวางแผนทั้ง 4 ทิศทางตอนนี้ · เลือก process แรกใน Starter Pack ก่อน · เมื่อมีอุปสรรคจริงให้เลือก 1 ทิศทางตามอาการที่พบ (หลัก "add by symptom" จาก AI Harness )
โบนัส: Eval set ตัวแรกใน 30 นาที
เด็คนี้พูดเสมอว่า "eval คือสินทรัพย์ที่ durable
ไม่ใช่ prompt" — นี่คือ วิธีสร้างจริง
สำหรับ process แรกของท่าน · ทำควบคู่กับขั้นที่ 4 ของ Starter Pack
(shadow mode) ได้
กำหนด 1 metric · ไม่ใช่หลาย
ตัวอย่าง: "% ของ priority labels ที่ตรงกับ ground truth" · เลือก metric ที่ business owner เซ็นอนุมัติได้ ไม่ใช่ technical metric · 1 metric ทำได้สมบูรณ์ ดีกว่า 5 metrics ทำได้ครึ่งๆ กลางๆ
รวบรวม 10 cases จาก history
หยิบ 10 cases จริงจาก process ที่ผ่านมา (เช่น customer feedback 10 ข้อความที่บุคคลจัดหมวดไว้แล้ว) · บันทึก input + expected output คู่กัน · 10 พอ ไม่ต้อง 100 · เก็บเป็น CSV หรือ markdown table
รัน prompt ผ่าน 10 cases ครั้งเดียว
ผ่าน Claude หรือ skill ของท่าน · เก็บ output ของแต่ละ case คู่กับ expected · ใช้ prompt เดิมที่จะ deploy · ไม่ปรับ prompt ตอนนี้
นับ accuracy ด้วยมือ
นับว่ามีกี่ cases ที่ตรงกับ expected (นับด้วยมือใน 5 นาทีก็เพียงพอ) · Target ≥ 80% สำหรับ first eval · หากต่ำกว่า ให้ปรับ prompt แล้วรันใหม่ · หากผ่าน → deploy ได้ทันที
เก็บใน skill repo · รันทุก deploy
วาง eval set ไว้ข้าง prompt ใน skill repo · ทุกครั้งที่ (ก) ปรับ prompt (ข) เปลี่ยน model → รัน eval ใหม่ · ถ้า accuracy ตก = ไม่ deploy · นี่คือ safety net ที่ข้าม model upgrade ได้
ทำไม eval อยู่ยงกว่า prompt
เมื่อ Opus 5 ออกในปีหน้า — prompt ของท่านจะ refactor · model ใหม่จะมีพฤติกรรมต่าง ·
แต่ eval set ของท่านยังใช้ได้ — รัน eval ผ่าน model ใหม่
ก่อน deploy · ถ้า accuracy ≥ 80% เหมือนเดิม → ปลอดภัย ·
ถ้าตก → รู้ตั้งแต่ก่อน deploy ว่า prompt ต้องปรับ ·
ดู Durable vs Disposable สำหรับหลักการเต็มรูปแบบ
สาระสำคัญ (Key Takeaway)
เลือก process 1 รายการก่อน ดำเนินการให้ครบทั้ง 5 ขั้น
แล้วจึงเริ่มรายการถัดไป
— การ automate 3 รายการพร้อมกัน = ล้มเหลว 3 รายการพร้อมกัน ·
ในช่วง 6 เดือนแรก การดำเนินงานตามลำดับให้ผลดีกว่าการทำขนาน
ทดสอบความเข้าใจ · Quick Check ใน 5 ขั้น
Starter Pack ขั้นใดที่ SME ส่วนใหญ่ "ข้าม" และเสียประโยชน์อะไร?
ขั้นที่ 4 (shadow mode 5 ครั้ง) — ส่วนใหญ่เร่ง
deploy โดยทันที · แต่ shadow mode คือ
eval ในระดับเริ่มต้น — หากข้ามขั้นนี้ จะ (1)
ไม่ทราบ baseline (2) เมื่อ Claude เกิดข้อผิดพลาด จะไม่มี data
สำหรับเปรียบเทียบ (3) ไม่มี ROI metric สำหรับนำเสนอต่อบอร์ด ·
สูญเสียทั้ง ความเชื่อมั่นจากทีม และ
ตัวเลขสำหรับนำเสนอต่อ CFO —
สองสิ่งที่ขาดไม่ได้สำหรับการขยายผล
คำถามที่พบบ่อย
FAQ
รวมคำถามที่ทุกห้องอบรมมักถามตรงกัน — คำตอบกระชับ พร้อมเปิดเวทีหารือเพิ่มเติม
ข้อมูลขององค์กรปลอดภัยหรือไม่ Claude นำไป train ต่อหรือไม่?
โดยค่าตั้งต้น prompt และไฟล์ที่ใช้งานใน business product จะ ไม่ ถูกนำไป train · สำหรับงานที่ sensitive เป็นพิเศษ องค์กรสามารถ deploy private endpoint และกำหนด logging/retention rule ของตนเองได้ · ในทางปฏิบัติ การใช้ Claude ปลอดภัยกว่าการส่งข้อมูลชุดเดียวกันให้ analyst ทาง email หากเปิดใช้ logging และ RBAC ตั้งแต่ Stage 3 ขึ้นไป
ค่าใช้จ่ายสำหรับ SME อยู่ในระดับใด?
สำหรับทีมขนาด 10 คน — โดยทั่วไปต้องการ seat 1–2 ที่นั่งสำหรับการรัน skill รายวัน เพิ่มเติมด้วยค่า API ของ scheduled mini-app · SME ส่วนใหญ่มีค่าใช้จ่ายอยู่ในระดับหลักร้อย USD ต่อเดือน และคืนทุนได้ตั้งแต่ process แรกที่ดำเนินการ automate
หาก Claude เกิด hallucination ระหว่าง workflow ควรจัดการอย่างไร?
มาตรการป้องกัน 3 ระดับ: (1) ground ทุกขั้นตอนกับไฟล์หรือ API ของจริง · ไม่ปล่อยให้โมเดลตอบจากความจำเพียงอย่างเดียว · (2) เพิ่ม sub-agent ทำหน้าที่ตรวจสอบผลลัพธ์เทียบกับ source · (3) ต้องมีบุคคลอยู่ใน loop เสมอสำหรับ action ที่ไม่สามารถย้อนกลับได้ (การเงิน, สัญญา, การลบข้อมูล)
ข้อมูลที่ Claude ใช้ ควรเก็บที่ใด?
Stage 2: ใช้ spreadsheet หรือ Drive ที่มีอยู่เดิมได้ · Stage 3: ใช้ ERP หรือ CRM ที่มีอยู่ผ่าน MCP connector (Claude อ่านที่ต้นทางโดยไม่ต้องทำสำเนา) · Stage 4+: data warehouse พร้อม lineage · แนวคิดหลักคือ ไม่ใช่การย้ายข้อมูลไปหา AI แต่ให้ AI เข้าถึงข้อมูล ณ ตำแหน่งที่จัดเก็บอยู่เดิม
หลีกเลี่ยง vendor lock-in ได้อย่างไร?
แยกออกเป็น 3 layer ที่ชัดเจน: (a) process เก็บในรูปแบบ BPMN — เป็นกลาง ไม่ผูกกับ vendor · (b) skill/prompt เก็บในรูปแบบ markdown — ย้ายไปใช้กับโมเดลอื่นได้ · (c) connector ใช้มาตรฐาน MCP — สลับ vendor ได้ · เมื่อแยกครบทั้ง 3 layer แล้ว จะคงเหลือเพียง model ที่ค่อนข้างสลับยาก
จำเป็นต้องมี data team หรือ engineer ก่อนเริ่มหรือไม่?
Stage 1–2 ยังไม่จำเป็น · Stage 3 ขึ้นไป ควรมีผู้รับผิดชอบอย่างน้อย 1 ตำแหน่งสำหรับ connector, eval และ rollout · SME ส่วนใหญ่จะรับบุคลากรตำแหน่ง AI-platform คนแรกเมื่อมี mini-app ใช้งานจริงประมาณ 3 ตัวขึ้นไป
วัด ROI อย่างไร?
(1) Business metric — ตัวเลขที่บอร์ดเข้าใจได้ทันที: กำหนด metric 1 ตัวต่อ process ก่อนเริ่มดำเนินการ — ชั่วโมงที่ประหยัดได้, จำนวน error ที่ตรวจจับได้, cycle time ที่ลดลง หรือรายได้ที่ป้องกันการสูญเสียได้ · เก็บ baseline ในช่วง shadow week (Starter Pack ขั้นที่ 4) · เมื่อครบ 90 วันจะมีข้อมูลเพียงพอสำหรับนำเสนอต่อบอร์ด · (2) Technical metric — สิ่งที่ CTO ต้องการ: Chip Huyen (AI Engineering , 2025) ได้แนะนำ 4 กลุ่มที่ต้อง track ควบคู่ไปกับ business metric — (ก) Quality (เช่น % accuracy เทียบกับ ground truth จาก eval set), (ข) Latency — TTFT (time-to-first-token), TPOT (time-per-output-token) และ total latency, (ค) Cost per inference (USD ต่อ run), (ง) Other เช่น interpretability และ fairness — สำคัญสำหรับงานที่ regulator จะเข้าตรวจ · หลักการ: business metric พิสูจน์ ROI ต่อบอร์ด · technical metric เปิดทางให้ทีม CTO และ Compliance ผ่านการตรวจสอบ และ scale ขึ้น stage ถัดไปได้
regulator หรือ auditor จะตรวจสอบในประเด็นใด?
BPMN ประกอบกับ run log ของ Claude และ policy markdown — รวมกันแล้วเป็นชุดหลักฐานที่ใช้ป้องกันตนเองได้อย่างมีน้ำหนัก · ควรหารือกับ auditor ตั้งแต่ระยะเริ่มต้นของ project · ส่วนใหญ่คุ้นเคยกับ process รูปแบบ AI-in-the-loop และมี checklist พร้อมใช้งานอยู่แล้ว
ข้อผิดพลาดที่ SME มักพบบ่อยที่สุดคือเรื่องใด?
การพยายาม automate process 3 อย่างพร้อมกันในเวลาเดียวกัน · แนะนำให้เลือกเพียง 1 รายการก่อน ดำเนินการให้ครบทั้ง 5 ขั้นของ Starter Pack แล้วจึงค่อยพิจารณารายการถัดไป · ในช่วง 6 เดือนแรก การดำเนินงานตามลำดับ (sequential) ให้ผลดีกว่าการทำขนาน (parallel) อย่างชัดเจน
ทำไม demo สนุก ๆ ในวันแรกถึงไม่กลายเป็น product ภายในเดือนเดียว? — เรื่องของ "Last Mile"
นี่คือกับดักที่พบบ่อยที่สุดสำหรับทีมที่เพิ่งเริ่มใช้ foundation model · capability ที่แข็งแรงของโมเดลทำให้สร้าง demo ที่ "ดูดี" ได้ภายในเวลาไม่กี่ชั่วโมง — แต่ระยะทางจาก demo ไปสู่ product ที่ใช้งานจริงในองค์กรนั้น ไกลกว่าที่คาดการณ์ไว้มาก · กฎที่ทีม AI engineering รุ่นใหญ่ยึดถือร่วมกัน คือ "จาก 0 → 60 นั้นง่าย · จาก 60 → 100 นั้นยากลำบาก" (อ้างอิง: UltraChat, Ding et al., 2023) · กรณีศึกษาจริง: ทีม LinkedIn (2024) ใช้เวลา 1 เดือนแรก สร้าง experience ให้ได้ 80% ของที่ต้องการ — แต่ต้องใช้อีก 4 เดือน หลังจากนั้น ไปกับการไล่จับ hallucination, edge case และ product kink เพื่อให้ผ่าน 95% · คำแนะนำเชิงปฏิบัติ: เมื่อนำเสนอ demo ของวันแรกต่อบอร์ดหรือลูกค้า ให้สื่อสารชัดเจนว่า "นี่คือ 60% — อีก 40% ที่เหลือจะใช้เวลามากกว่าทั้งหมดที่ผ่านมารวมกัน" · การบริหารความคาดหวังตั้งแต่ต้นจะช่วยลด pressure ระหว่างทางได้อย่างมีนัยสำคัญ
"Agent Harness" คืออะไร และ SME จำเป็นต้องมีหรือไม่?
Harness คือชั้น scaffolding ที่ห่อหุ้มโมเดล (orchestration loop, tools, memory, context management, state, guardrails) เพื่อให้ทำงานในลักษณะ agent ·
ทุกองค์กรมี harness อยู่แล้ว ในทุกครั้งที่รัน Claude พร้อม tool use · คำถามที่แท้จริงคือ "อยู่ในระดับใด" — Stage 1–2 ใช้ harness สำเร็จรูป (Claude Agent SDK) ก็เพียงพอแล้ว · Stage 3+ จึงควรพิจารณา custom harness · ข้อแนะนำของ Anthropic คือเริ่มต้นที่ระดับ 2–4 ชั่วโมงและ 20–50 บรรทัด แล้วค่อยเพิ่ม component
ตามอาการที่พบ ไม่ใช่ติดตั้งครบทุกอย่างตั้งแต่ต้น · ดูรายละเอียดเพิ่มเติมที่
slide AI Harness
จะหลีกเลี่ยงการสร้างสิ่งที่ obsolete ภายใน 1 ปีได้อย่างไร?
หลักสำคัญ 3 ประการ: (1)
วาด BPMN ก่อนเขียน prompt — process แทบไม่เปลี่ยนแปลงแม้เครื่องมือจะเปลี่ยน · (2)
แยก layer ให้ชัดเจน : process / skill / connector / model — เปลี่ยน layer ล่างได้โดยไม่กระทบ layer บน · (3)
ลงทุนในทักษะของทีม ไม่ใช่ใน tool ของ vendor — "ทีมเข้าใจวิธี automate process" คือสินทรัพย์ขององค์กร ส่วน "ทีมใช้ Tool X เป็น" คือต้นทุนเช่าใช้ · ดู
slide Durable vs Disposable สำหรับ checklist ฉบับสมบูรณ์
ESG reporting ดูเป็นภาระมาก AI ช่วยตรงไหนได้บ้าง?
ลำดับการใช้ AI ที่สร้าง ROI สูงสุดสำหรับ ESG: (1)
การ extract ข้อมูล จากระบบหลายแหล่ง เช่น Scope 2 จาก utility bill หรือ supplier attestation 1,000+ ราย — ลดเวลาจากสัปดาห์เหลือชั่วโมง · (2)
การร่าง narrative จากข้อมูลตัวเลข — เนื่องจากทีมความยั่งยืนใช้เวลาส่วนใหญ่กับการเขียน ไม่ใช่การวิเคราะห์ · (3)
การ monitor compliance อย่างต่อเนื่อง แทนการ audit รายไตรมาส · (4)
การสังเคราะห์ board report จากแหล่งข้อมูลหลายแหล่ง · แนะนำให้เริ่มจากข้อ 1 ใน Scope 2 ก่อน แล้วค่อยขยายไปยัง social และ governance · ดูรายละเอียดที่
slide ESG
การใช้ AI เองมีผลต่อ ESG ขององค์กรในด้านใด?
3 ด้านที่ต้องบริหาร: (E)
energy footprint — เลือก model ที่ขนาดเหมาะสมกับงาน ไม่จำเป็นต้องใช้ Opus สำหรับทุกอย่าง · (S)
bias และ accessibility — โดยเฉพาะการตัดสินใจที่กระทบบุคคลโดยตรง เช่น hiring, lending หรือ promotion · (G)
AI governance — model card, eval log, RBAC, audit trail · ทั้งหมดเชื่อมโยงโดยตรงกับ 6 component ของ
AI Harness โดยเฉพาะส่วน guardrails และ observability
จบ workshop · ก้าวต่อไป
ถ่ายภาพ BPMN ของท่านและส่งให้ facilitator — ทีมงานจะ check-in กลับภายใน 14 วัน